Menu
Are All Delimited-String Parsers Created Equal?
By Jeffry Schwartz | Function
In short, no. However, for many years there was no alternative to the T-SQL option, and even when there were other viable options, it was unclear whether it was worth changing existing code to take advantage of the new technologies. With the addition of the string_split function in SQL Server 2016, it is worth revisiting this topic. This article will discuss three different methods (T-SQL, C# CLR, and string_split) for breaking delimited strings into result sets and compare their performance across varying length lists. Three different T-SQL functions will be tested along with the C# CLR and string_split methods. The examples provided employ numerical lists delimited by commas and return either strings or integers to determine whether there is a significant performance difference when numbers are converted from strings to integers.
To ensure as much consistency as possible, a series of random numbers were generated and merged into varying-length lists of 20, 50, 75, 100, 150, 500, 1000, 1500, 2500, and 5000 integers. Although the list from which the test strings were derived contained random numbers, the same list was used as input for each of the tests, i.e., the first 20 elements of all tests were identical. Query results were discarded because allowing them to be returned warped the final run times badly, increasing them by at least a factor of FOUR, even when the results were written to a file! An example of a list of 20 is as follows: select * from dbo.fcn_SplitCSV (‘7503, 87355, 74205, 3985, 5811, 1286, 94488, 33989, 8642, 17592, 80938, 48701, 84713, 430, 54960, 46492, 9916, 38679, 89117, 5703’). The full T-SQL invocation code for the 20-element test of fcn_SplitCSV is shown below. As evidenced by the code, each test was performed 2,500 times to minimize the probability that any individual variations would skew the final results.
-- `20`2500`convert to int`fcn_SplitCSV`
set nocount on;
declare @inx int = 0
declare @maxinx int = 2500
while @inx < @maxinx
begin
select * from dbo.fcn_SplitCSV ('7503, 87355, 74205, 3985, 5811, 1286, 94488, 33989, 8642, 17592, 80938, 48701, 84713, 430, 54960, 46492, 9916, 38679, 89117, 5703')
set @inx += 1
end
go
In addition to the three major methods cited above, two other variations were tested: conversion of strings to numbers in the result set and specifying a delimiter using a string variable instead of a string constant. Each test was performed in its own batch on an otherwise idle system. Run-time performance was captured using an Extended Events session, which was configured to capture sqlserver.sql_batch_completed events ONLY. The session definition, start, and stop code are shown below. This session collects information for completed batches that ran longer than 10 microseconds and were executed from database #7.
use master;
IF EXISTS(SELECT * FROM sys.server_event_sessions WHERE name='SQLRxPerformanceMonitoring')
DROP EVENT session SQLRxPerformanceMonitoring ON SERVER
GO
-- replace database_id(s) with list
CREATE EVENT SESSION SQLRxPerformanceMonitoring ON SERVER
ADD EVENT sqlserver.sql_batch_completed(
SET collect_batch_text=(1)
ACTION(sqlserver.server_instance_name, sqlserver.database_id, sqlserver.session_id, sqlserver.client_pid, sqlserver.client_app_name, sqlserver.database_name, sqlserver.server_principal_name, sqlserver.client_hostname, sqlserver.tsql_frame, sqlserver.tsql_stack, sqlserver.sql_text, sqlserver.request_id, sqlserver.query_hash, sqlserver.query_plan_hash, package0.event_sequence)
WHERE ([duration]>(10) and (database_id = 7))
) -- replace database_id
ADD TARGET package0.event_file(SET filename= N'E:\SQLRx\SQLScriptOutput\DevPerf.xel')
WITH (MAX_MEMORY=4096 KB, EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS, MAX_DISPATCH_LATENCY=5 SECONDS, MAX_EVENT_SIZE=0 KB, MEMORY_PARTITION_MODE=NONE, TRACK_CAUSALITY=OFF, STARTUP_STATE=OFF)
GO
-- entry exists when session is active
if not exists(select * from [master].[sys].[dm_xe_sessions] where [name] = 'SQLRxPerformanceMonitoring')
alter EVENT SESSION SQLRxPerformanceMonitoring ON SERVER STATE = START
-- entry exists when session is active
if exists(select * from [master].[sys].[dm_xe_sessions] where [name] = 'SQLRxPerformanceMonitoring')
alter EVENT SESSION SQLRxPerformanceMonitoring ON SERVER STATE = STOP
Three different T-SQL functions were used for testing. Each of the functions used different T-SQL logic to parse the string, and one of them was modified to use a delimiter, specified in a variable as opposed to using a string constant. The code for the three T-SQL functions: fn_CSVToTable, fcn_SplitCSV, and fcn_SplitStringListDelimiter, is shown below:
-- fn_CSVToTable
CREATE Function [dbo].[fn_CSVToTable]
(
@CSVList Varchar(max)
)
RETURNS @Table TABLE (ColumnData VARCHAR(100))
AS
BEGIN
IF RIGHT(@CSVList, 1) <> ','
SELECT @CSVList = @CSVList + ','
DECLARE @Pos BIGINT,
@OldPos BIGINT
SELECT @Pos = 1,
@OldPos = 1
WHILE @Pos < LEN(@CSVList)
BEGIN
SELECT @Pos = CHARINDEX(',', @CSVList, @OldPos)
INSERT INTO @Table
SELECT LTRIM(RTRIM(SUBSTRING(@CSVList, @OldPos, @Pos - @OldPos))) Col001
SELECT @OldPos = @Pos + 1
END
RETURN
END -- fn_CSVToTable
go
-- fcn_SplitCSV
CREATE FUNCTION [dbo].[fcn_SplitCSV] ( @NumberList varchar(max))
RETURNS @SplitList TABLE ( ListMember INT )
AS
BEGIN
DECLARE @Pointer int, @ListMember varchar(256)
SET @NumberList = LTRIM(RTRIM(@NumberList))
IF (RIGHT(@NumberList, 1) != ',')
SET @NumberList=@NumberList+ ','
SET @Pointer = CHARINDEX(',', @NumberList, 1)
IF REPLACE(@NumberList, ',', '') <> ''
BEGIN
WHILE (@Pointer > 0)
BEGIN
SET @ListMember = LTRIM(RTRIM(LEFT(@NumberList, @Pointer - 1)))
IF (@ListMember <> '')
INSERT INTO @SplitList
VALUES (convert(int,@ListMember))
SET @NumberList = RIGHT(@NumberList, LEN(@NumberList) - @Pointer)
SET @Pointer = CHARINDEX(',', @NumberList, 1)
END
END
RETURN
END
GO -- fcn_SplitCSV
-- fcn_SplitStringListDelimiter
CREATE FUNCTION [dbo].[fcn_SplitStringListDelimiter] (@StringList VARCHAR(MAX), @Delimiter varchar(2))
RETURNS @TableList TABLE( StringLiteral VARCHAR(128))
BEGIN
DECLARE @StartPointer INT, @EndPointer INT
SELECT @StartPointer = 1, @EndPointer = CHARINDEX(@Delimiter, @StringList)
WHILE (@StartPointer < LEN(@StringList) + 1)
BEGIN
IF @EndPointer = 0
SET @EndPointer = LEN(@StringList) + 1
INSERT INTO @TableList (StringLiteral) VALUES(LTRIM(RTRIM(SUBSTRING(@StringList, @StartPointer, @EndPointer - @StartPointer))))
SET @StartPointer = @EndPointer + 1
SET @EndPointer = CHARINDEX(@Delimiter, @StringList, @StartPointer)
END -- WHILE
RETURN
END -- fcn_SplitStringListDelimiter
GO
The C# CLR function, tvf_SplitString_Multi, is shown below followed by its T-SQL definition:
[Microsoft.SqlServer.Server.SqlFunction(IsDeterministic = true, DataAccess = DataAccessKind.None, FillRowMethodName = "FillRow_Multi", TableDefinition = "item nvarchar(4000)")]
public static IEnumerator tvf_SplitString_Multi(
[SqlFacet(MaxSize = -1)]
SqlChars Input,
[SqlFacet(MaxSize = 255)]
SqlChars Delimiter
)
{
return (
(Input.IsNull || Delimiter.IsNull) ?
new SplitStringMulti(new char[0], new char[0]) :
new SplitStringMulti(Input.Value, Delimiter.Value));
}
public static void FillRow_Multi(object obj, out SqlString item)
{
item = new SqlString((string)obj);
}
public class SplitStringMulti : IEnumerator
{
public SplitStringMulti(char[] TheString, char[] Delimiter)
{
theString = TheString;
stringLen = TheString.Length;
delimiter = Delimiter;
delimiterLen = (byte)(Delimiter.Length);
isSingleCharDelim = (delimiterLen == 1);
lastPos = 0;
nextPos = delimiterLen * -1;
}
#region IEnumerator Members
public object Current
{
get
{
return new string(theString, lastPos, nextPos - lastPos);
}
} // Current
public bool MoveNext()
{
if (nextPos >= stringLen)
return false;
else
{
lastPos = nextPos + delimiterLen;
for (int i = lastPos; i < stringLen; i++)
{
bool matches = true;
//Optimize for single-character delimiters
if (isSingleCharDelim)
{
if (theString[i] != delimiter[0])
matches = false;
}
else
{
for (byte j = 0; j < delimiterLen; j++)
{
if (((i + j) >= stringLen) || (theString[i + j] != delimiter[j]))
{
matches = false;
break;
}
}
}
if (matches)
{
nextPos = i;
//Deal with consecutive delimiters
if ((nextPos - lastPos) > 0)
return true;
else
{
i += (delimiterLen - 1);
lastPos += delimiterLen;
}
}
}
lastPos = nextPos + delimiterLen;
nextPos = stringLen;
if ((nextPos - lastPos) > 0)
return true;
else
return false;
}
} // MoveNext
public void Reset()
{
lastPos = 0;
nextPos = delimiterLen * -1;
} // Reset
#endregion
private int lastPos;
private int nextPos;
private readonly char[] theString;
private readonly char[] delimiter;
private readonly int stringLen;
private readonly byte delimiterLen;
private readonly bool isSingleCharDelim;
} // SplitStringMulti
CREATE FUNCTION [dbo].[tvf_SplitString_Multi](@DelimitedItemList nvarchar(max), @Delimiter nvarchar(255)) RETURNS TABLE (Item NVARCHAR(4000)) AS EXTERNAL NAME [ParseTraceQueryText].[MySPs.TableValuedFunctions].[tvf_SplitString_Multi] GO
The final piece of the testing puzzle involves the simple invocation of the string_split function that is documented via this link: https://docs.microsoft.com/en-us/sql/t-sql/functions/string-split-transact-sql?view=sql-server-2016.
Although the author believed that the conversion of strings to integers and specifying a delimiter using a variable instead of a string constant might result in a discernible performance difference, these hypotheses were not supported by the test results. However, significant performance differences were observed between the T-SQL and compiled-code (C# CLR and string_split) solutions. Interestingly, the solutions performed similarly until the number of elements exceeded 150, at which point they diverged significantly.
The first two execution time graphs below, one with normal scaling and the other with truncated scaling, highlight the divergence of the two solutions. As these graphs illustrate, the compiled-code solutions scaled extremely well all the way up to 1,500 elements. They increase slightly after this point, but performance was still quite good, peaking at three milliseconds. The same cannot be said for the T-SQL solutions, all of which peaked over 70 milliseconds. Clearly, if these routines are executed a few times or parse very small lists, all of these solutions are acceptable. However, if the parsing routine is executed thousands of times or the number of elements is long, the choice would be very important. To emphasize this point, 2,500 executions of fn_CSVToTable took a total of 33 seconds for a list of 1,500 elements, whereas the string_split solution required only 0.45 seconds to complete the same amount of work. This disparity becomes even greater when the length of the parsed list reaches 5,000 elements. fn_CSVToTable required 180 seconds to complete 2,500 iterations, whereas string_split required only eight seconds.
Two other metrics were noteworthy: logical reads and row counts. As shown in Figure 3, the two compiled-code solutions performed almost no logical reads, whereas the T-SQL ones performed thousands to millions. Secondly, as shown in Figure 4, the row counts of the T-SQL methods were approximately five times higher than those of the compiled-code. The execution plans for the five routines explain why the metrics were so different. As shown in Figure 5 through Figure 9, despite the fact that each T-SQL routine is different, all of them generated table scans in addition to the table valued function calls, whereas the compiled-code ONLY generated the table valued function calls.
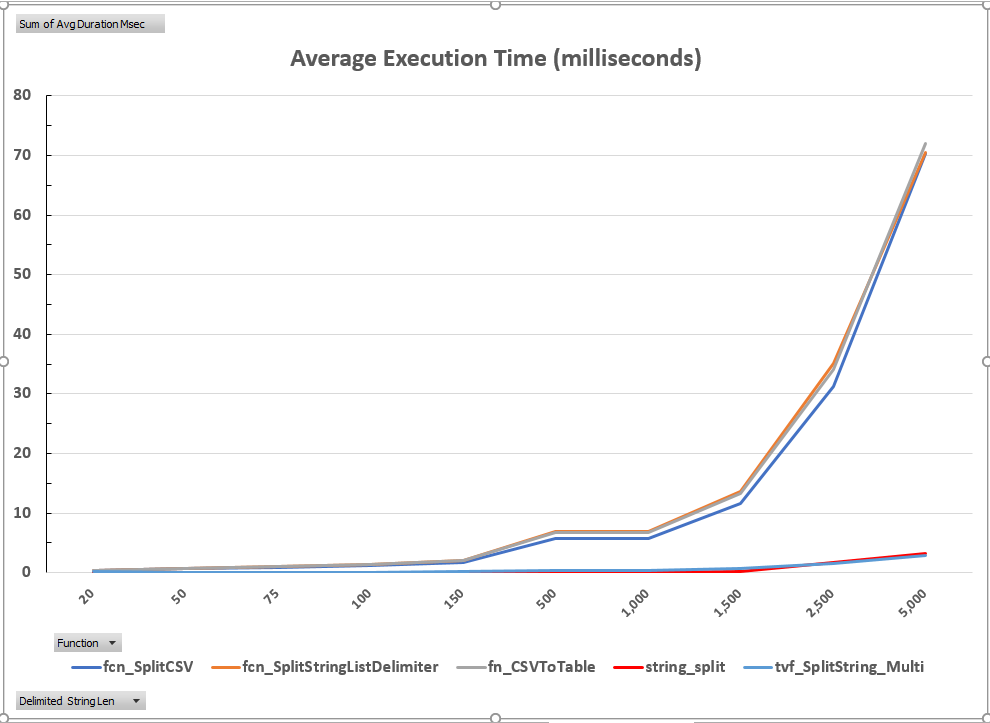
Figure 1: Average Execution Time – Normal Scaling
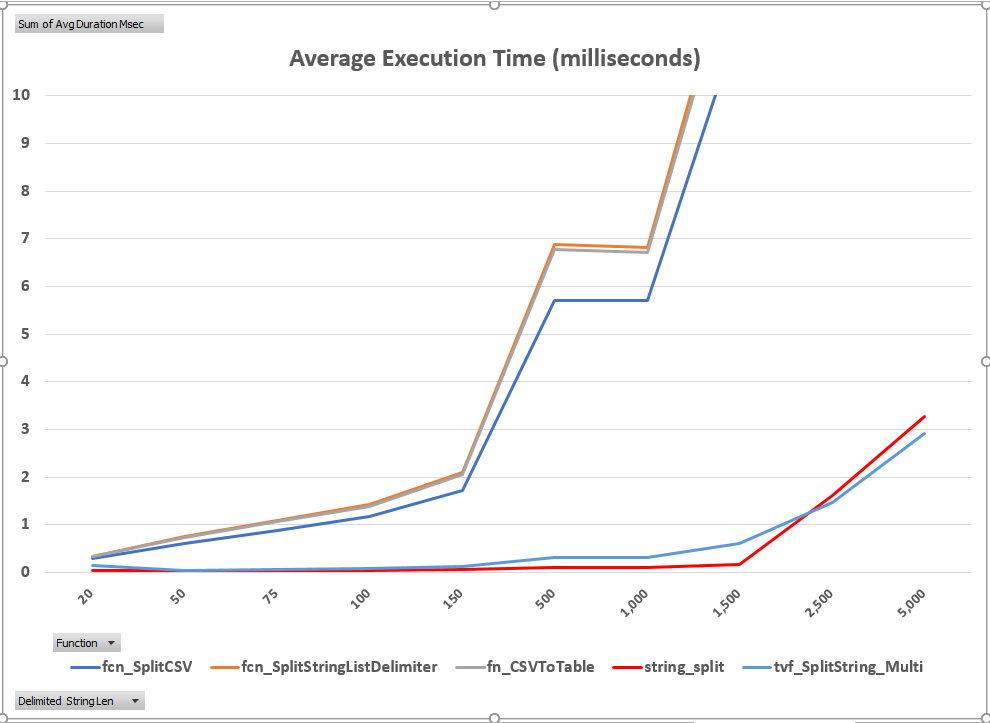
Figure 2: Average Execution Time – Truncated Scaling
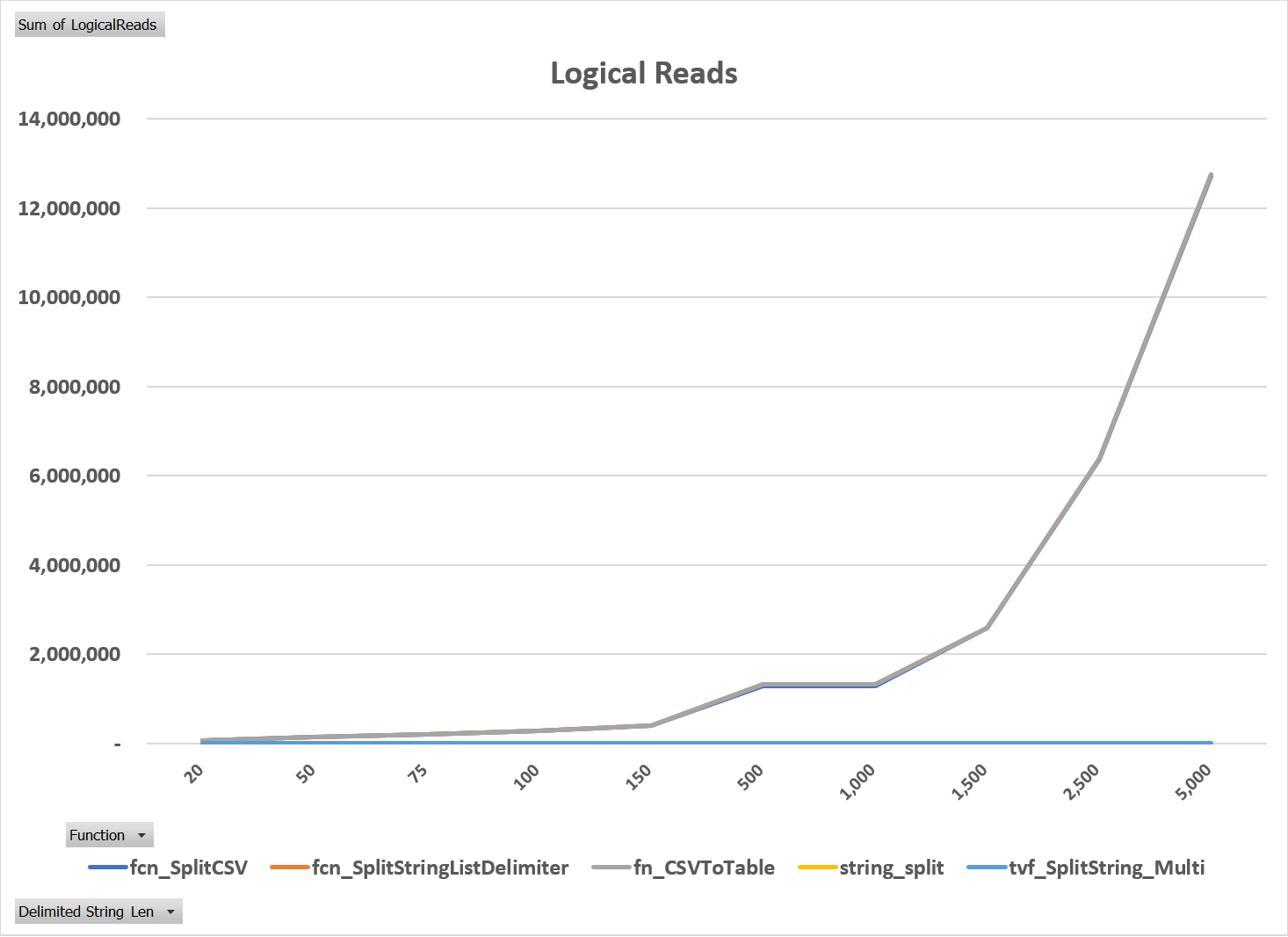
Figure 3: Logical Reads
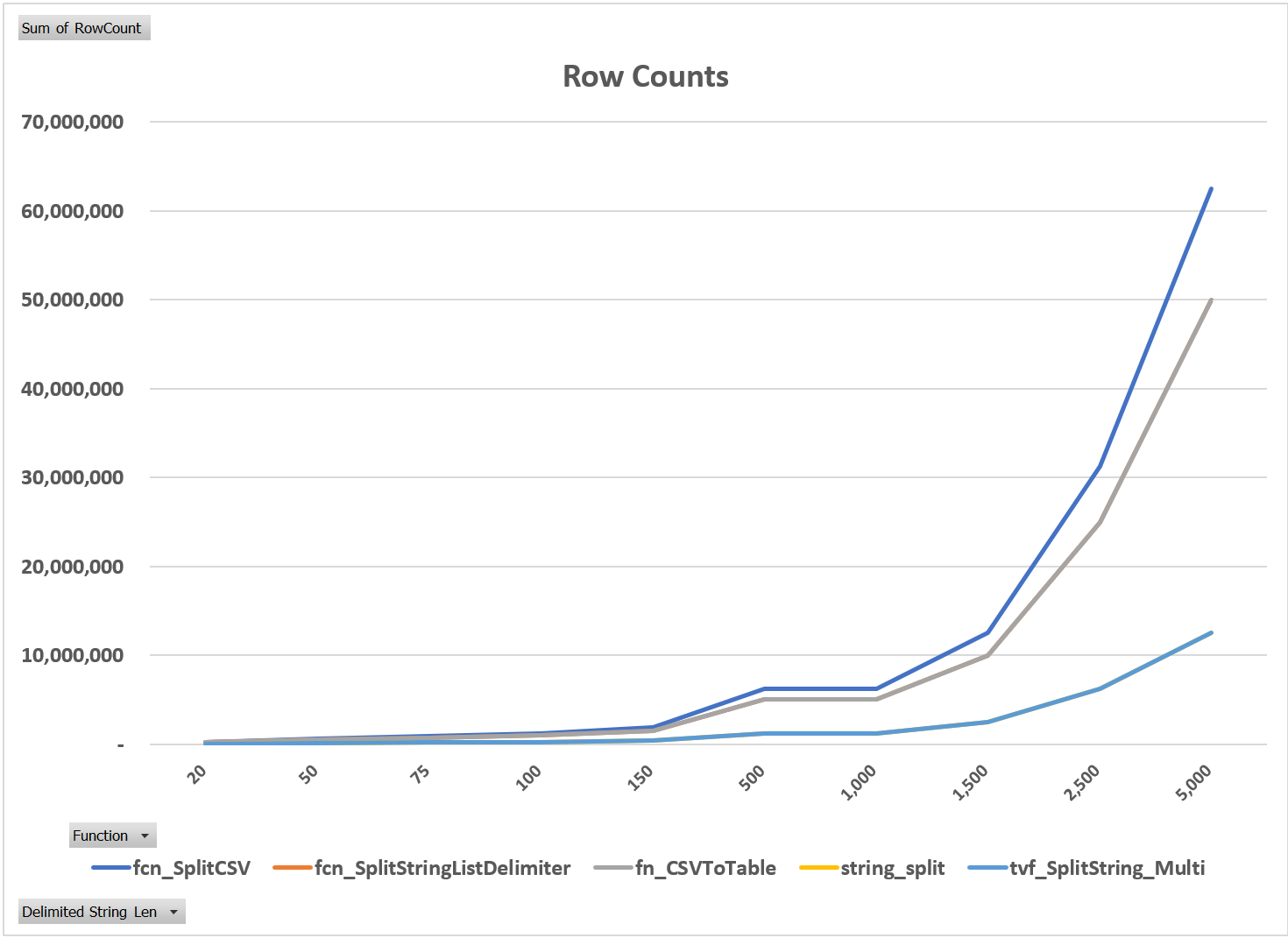
Figure 4: Row Counts
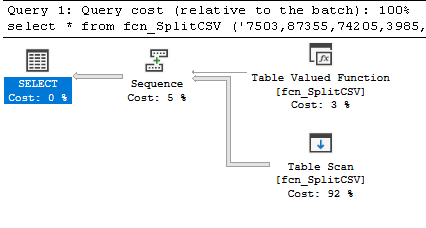
Figure 5: fcn_SplitCSV Execution Plan
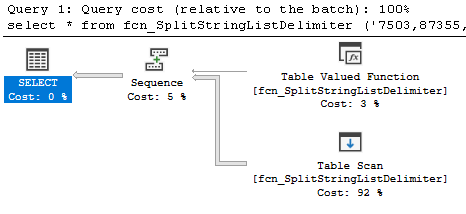
Figure 6: fcn_SplitStringListDelimiter Execution Plan
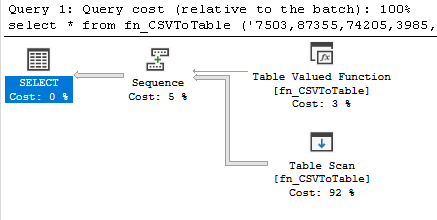
Figure 7: fn_CSVToTable Execution Plan
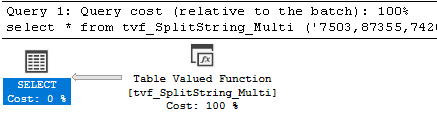
Figure 8: tvf_SplitString_Multi Execution Plan
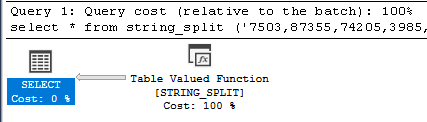
Figure 9: String_Split Execution Plan
In summary, existing T-SQL code need not be replaced unless it is expected to parse lists of more than 150 elements or be executed thousands of times. However, if possible, new development that will run on SQL Server 2016 or higher should use the string_split function.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. We love to talk tech with anyone in our SQL family!