Menu
Index REORGANIZE Generates Out of Space Messages
By Lori Brown | Indexes
I was doing some performance analysis at a client where we captured a traditional SQL trace. Our client has SQL 2016 Enterprise that is fully patched up and uses Ola Hallengren’s IndexOptimize (https://ola.hallengren.com/) stored proc to do nightly index maintenance. While the index maintenance ran, we caught over a hundred thousand Error 1105, Severity 17, State 2 – “Could not allocate space for object ‘<object_name>’ in database ‘<database_name>’ because the ‘PRIMARY’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup.” – error messages that exclusively happened when REORGANIZE is specified in the ALTER INDEX statement.
We thought that there must be a problem with space or the growth settings on the database or tempdb but found that there is plenty of space on all drives, there is plenty of free space in the data files, autogrowth is turned on and the growth was set to 500MB for each file, tempdb also had plenty of space and no issues with setting or file sizes. In my experience, when a file cannot grow when it needs to, SQL will also write this error message to the SQL logs. To further confuse us we did not find this matching error message in any of the SQL logs, only in the SQL trace. Since I have the trace files, I took some time to go through it and could see that any time an index REBUILD was run it did not cause the error to be thrown, but any time an index REORGANIZE was run it did. Dang.
I decided to try to replicate the errors on my own SQL 2016 instance on one of our databases and was easily able to do so just by running ALTER INDEX…REORGANIZE and DBCC INDEXDEFRAG statements. None of these errors were written to the SQL logs. Interestingly, using the Reorganize Index Task in a SQL Maintenance Plan did not cause the out of space errors.
ALTER INDEX [ix_EvtRowChksum] ON [WinPerfDataSQL].[dbo].[CompletedEventText] REORGANIZE
Generates the error….
Could not allocate space for object ‘dbo.CompletedEventText’.’ix_EvtRowChksum’ in database ‘WinPerfDataSQL’ because the ‘PRIMARY’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup.
DBCC INDEXDEFRAG (WinPerfDataSQL, ‘dbo.DeadlockProcesses’, PK_DeadlockProcesses)
Generates the error….
Could not allocate space for object ‘dbo.DeadlockProcesses’.’PK_DeadlockProcesses’ in database ‘WinPerfDataSQL’ because the ‘PRIMARY’ filegroup is full. Create disk space by deleting unneeded files, dropping objects in the filegroup, adding additional files to the filegroup, or setting autogrowth on for existing files in the filegroup.
Here are some screen shots of drive space and database settings along with the results of sys.dm_server_services to show that Instant File Initialization is enabled.
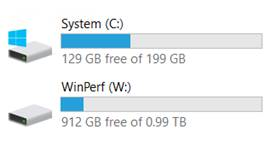
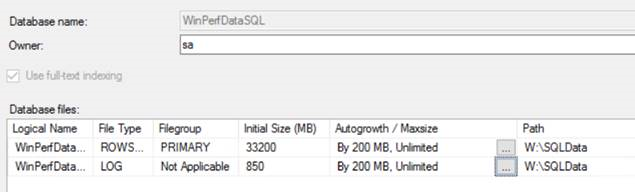

While I can see that there is not really a space issue, I was still wondering why SQL is throwing the 1105 messages during REORGs. Is this by design or is this a bug?
After a quick consultation with Paul Randal ( Blog | Twitter ) (I figured I should ask the guy who would know best.), he informed me that “It appears to be a by-design/bug in later versions that’s documented (https://docs.microsoft.com/en-us/sql/relational-databases/indexes/reorganize-and-rebuild-indexes?view=sql-server-2017). Nothing you can do except to rebuild instead of reorganize. “
I had indeed missed this note tucked in the Microsoft Online Document:
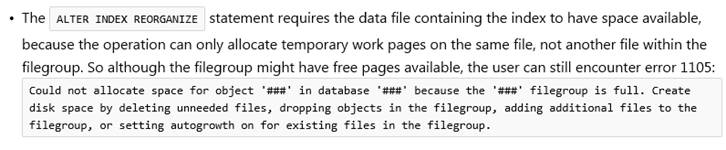
As of this writing, our super smart SQL Architect and Performance Expert (Jeff Schwartz) is working on some testing to see if there is any measurable overhead to all the misleading out-of-space messages generated during index REORGANIZE maintenance. So stay tuned as we should have a follow up post soon on his findings and recommendations for index REBUILD or REORGANIZE thresholds.
If you find error 1105 messages in your trace or xevents session, always investigate them fully. Don’t assume they come from index maintenance unless you absolutely track to the source and know that you do have space on your drives and data files.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. We love to talk tech with anyone in our SQL family!