Menu
List All Objects and Indexes in a Filegroup or Partition
By Lori Brown | Intermediate
— by Lori Brown @SQLSupahStah
One of my clients has a rather large database with multiple filegroups and multiple database files in them. I happened to notice that a specific drive that is occupied by 2 specific files that are supposed to hold indexes is getting utilized at a much higher rate than any of the other files. The index file group has 8 files in it. I was anticipating gathering some performance data to try to figure out what indexes are located on those specific files and needed a way to figure that out. My searching for a script led me to TechNet where there are a bunch of scripts that are freely downloadable. The one I needed came Olaf Helper. I added a join on the database files so that I could see what file they are on and filter on that.
Since I need to join my query to the actual database files, I needed to figure out what the file_id was for the specific files that I am interested in.
SELECT * FROM sys.database_files
This is a very modified output so you can see the different filegroups and the files in them.
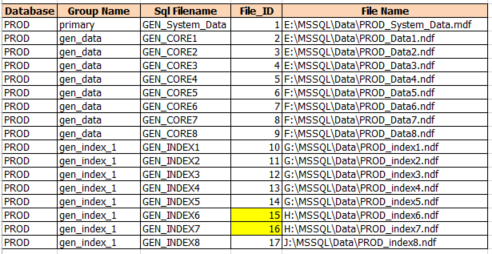
Checking the data in sys.database files will give you the answer. https://msdn.microsoft.com/en-us/library/ms174397.aspx
Anyway, put it all together and mine looks like this:
SELECT DS.name AS DataSpaceName
,f.physical_name
,AU.type_desc AS AllocationDesc
,AU.total_pages / 128 AS TotalSizeMB
,AU.used_pages / 128 AS UsedSizeMB
,AU.data_pages / 128 AS DataSizeMB
,SCH.name AS SchemaName
,OBJ.type_desc AS ObjectType
,OBJ.name AS ObjectName
,IDX.type_desc AS IndexType
,IDX.name AS IndexName
FROM sys.data_spaces AS DS
INNER JOIN sys.allocation_units AS AU
ON DS.data_space_id = AU.data_space_id
INNER JOIN sys.partitions AS PA
ON (AU.type IN (1, 3)
AND AU.container_id = PA.hobt_id)
OR
(AU.type = 2
AND AU.container_id = PA.partition_id)
JOIN sys.database_files f
on AU.data_space_id = f.data_space_id
INNER JOIN sys.objects AS OBJ
ON PA.object_id = OBJ.object_id
INNER JOIN sys.schemas AS SCH
ON OBJ.schema_id = SCH.schema_id
LEFT JOIN sys.indexes AS IDX
ON PA.object_id = IDX.object_id
AND PA.index_id = IDX.index_id
WHERE f.file_id IN (13,14) AND AU.total_pages > 0 — Look at specific files, could also filter on file group
ORDER BY AU.total_pages desc — Order by size
–DS.name
–,SCH.name
–,OBJ.name
–,IDX.name
The output looks like this…I sorted on size but left the columns needed to sort by name:
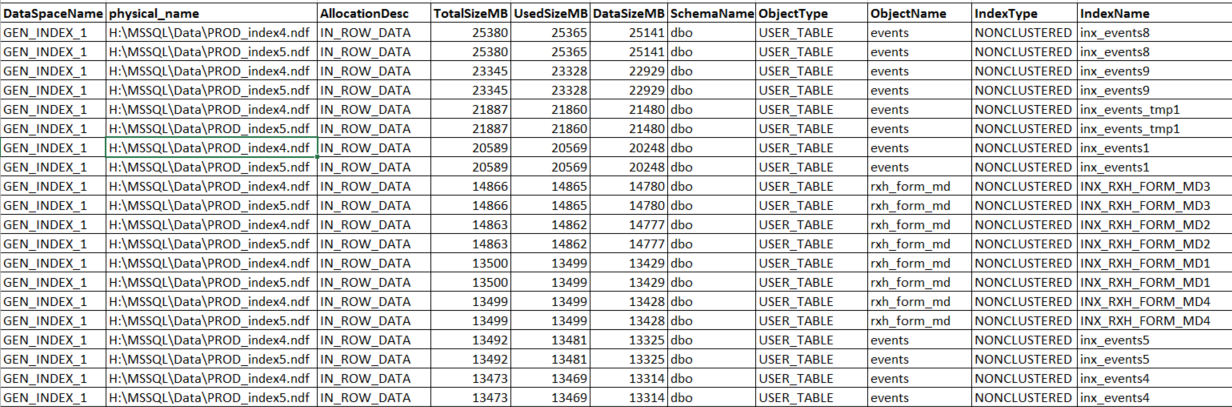
Now I am ready to collect performance data to see what stressful queries are using the indexes located on these files.
I don’t have the results from the performance data just yet but will likely follow up later on putting all the pieces together to solve this very specific problem.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. Visit us at www.sqlrx.com!