Menu
Table-Valued Parameter Performance Using C# Data Tables
By Jeffry Schwartz | Expert
The following testing and resulting data is a direct result of a recent issue that was discovered at one of our client sites. After setting up SQL monitoring that does use a SQL trace to capture long running queries, suddenly certain processes would lock up and be unable to complete. Initially we thought it was everything except the SQL trace causing the issue until we finally turned off all trace captures and the problem went away. This was very concerning to us since using either SQL trace or XEvents is the method that we generally use to capture query performance. Without a fix, our performance tuning attempts would be severely hamstrung and slowed down. This problem had to be fixed yesterday!
Another side effect that would happen when things locked up was that despite having the max server memory set, SQL would end up using substantially more memory that was allocated to it. At this client, developers were importing data from an application using C# and table-valued parameters which should have not been an issue. After a lot of searching, we finally came across some comments by another SQL expert who mostly described our issue and recommended that any C# TVP’s should have their columns defined or SQL could lock up if either trace or XEvents Completed Events are captured. When we checked the C# code we found that the string columns that were being imported were not defined in an effort to make the import code flexible. We were able definitively fix this very obscure problem with just one line of C# code that is in the below post. The end result is a FASTER import of data that can be captured in trace or XEvents. Nice!!
Since we had to put together this fix for a very undocumented issue, we sincerely hope that any DBA or developer who runs into this problem can correct it much faster than we did. A link to download a zip file of all code displayed in this post is included at the end. Enjoy!
********************************************
— By Jeff Schwartz
Much has been written about the use of table-valued parameters (TVP) and their performance. These narratives appear to be contradictory because some state that TVPs should be used only for small datasets, whereas others assert that TVPs scale very well. Adding to the confusion is that the fact that most of the performance-related discussions focused on TVP use within T-SQL. Many of these examples employ either SQL trace or Extended Events (XEvents) to evaluate performance, but almost none of them has discussed what can occur when C# data tables and SQL trace or XEvents are used simultaneously. This paper details the analysis and resolution of a situation that occurred at a customer site when an existing C# application suddenly began to run extremely slowly after a very lightweight SQL trace that utilized a several-minute duration threshold and captured no frequent events was activated.
Preliminary research indicated that under very specific conditions the combination of TVPs and SQL trace could result in unintended performance consequences, e.g., excessive SQL Server memory consumption to the point where SQL Server exhausted all memory on the server regardless of the maximum memory setting value. The research also suggested that string usage and lengths in unspecified locations might have an impact on this issue. The question of whether TVPs might have some record-count performance threshold above which performance would degrade was also examined. Although bulk insert was not used by the application, the research team also decided to compare bulk and TVP insertion speeds because that is another source of conflicting information.
Since very little literature exists that discusses the combination of TVPs and SQL trace, the only recourse involved creating test frameworks, performing actual data loads, and using internal application timers in conjunction with either SQL trace or XEvents to monitor performance.
1.Two frameworks were constructed: T-SQL-only and C# calling a T-SQL stored procedure.
a. The T-SQL-only test loaded data into a TVP, which then called a stored procedure to perform the insertion into the final table.
b. The development team provided C# code that illustrated how the user application read a flat file into a C# data table, which was then passed as a TVP to a T-SQL stored procedure. This code was followed as closely as possible in the test framework.
2.A SQL server table containing data captured from the sys.dm_db_index_operational_stats Data Management View (DMV) supplied the data for testing because
a. The data table contained approximately 3.2 million records, thereby being large enough to stress the application code and SQL Server adequately. The largest data file provided by the application team was approximately 1.6 million records, so the testing could push well beyond current record levels.
b. Each data record contained 47 columns, which was wider in terms of data columns than any application table being loaded.
c. No string value columns existed in the data. This insured that user string data could not affect any interaction between the C# application and SQL Server, and that any string-related behavior was strictly due to the manner in which the application loaded the data table or the TVP, or the way the TVP parameter-passing was recorded in the SQL trace. All data columns were smallint, int, bigint, or date. This also insured exact record lengths so that any record count-related behavior was independent of record size. Some of the data files being loaded by the development team contained only fixed-width data types, whereas others contained at least a few variable length string columns.
3.The frameworks were designed to load various numbers of records using the same starting point to determine whether a performance threshold existed for TVPs, regardless of whether SQL trace (or XEvents) was active, as well as to determine whether even small numbers of records could be processed with the SQL trace (or XEvents) active.
4.Thirty-one different record levels, shown in Table 1, were used for testing to insure any record-count gaps were small. A separate CSV file of each length was created from the data cited in #2, always beginning with the first record.
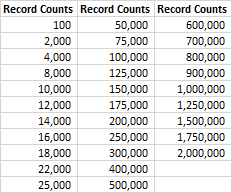
Table 1: Record Counts used in Testing
5.Several methods of loading the flat file CSV data into C# data tables were developed and tested. The C# data table configurations were as follows:
a. Unlimited string length columns (initially used in the production C# application) – herein noted as NoStringMax (String #N/A on graphs)
b. Fixed length string columns of at most 30, 100, 500, or 1000 characters each – herein noted as StringMax (String <#> on graphs). Note: the development team stated that no column would exceed 1,000 characters in length.
c. Exact data type mapping so that the data table column types matched those of the receiving SQL Server table exactly – herein noted as Map
d. A common routine was used by options a, b, and c above to send the data table to SQL Server using a TVP.
e. The section of code that loaded the data table from the flat file was timed separately from the routine cited in d, which also was surrounded by its own timers. This enabled comparison of data load, TVP passing, and combined times.
f. The name of the CSV file is passed in as a parameter along with an adjusted version of the file name so the appropriate test identifiers can be written to the application log file for later analysis.
6.The tests were run with the following SQL Server monitoring options:
a. No SQL Server monitoring at all.
b. SQL trace monitoring including all normally captured events except for completed ones. These were handled as follows:
i.Exclude all completed events
ii.Include ad-hoc and batch completed events with a two-second duration threshold
iii.Include ad-hoc and batch completed events as well as completed statement events with a two-second duration threshold
c. SQL Extended Events (XEvents) including all normally captured events except for completed ones. These were handled as follows:
i.Exclude all completed events
ii.Include ad-hoc and batch completed events with a two-duration threshold
iii.Include ad-hoc and batch completed events as well as completed statement events with a two-duration threshold
7.All tests were performed on the same server to eliminate network and hardware variability. This server had a quad-core Intel(R) Core(TM) i7-4700MQ CPU @ 2.40GHz processor, 32 GB of RAM, and a 500 GB SSD HD.
8.Various combinations of cold and warm SQL Server caches, cold and warm Windows caches, and SQL Server maximum memory limit sizes were tested. Some of the earlier attempts will be discussed in the Results section below. The final specifications were as follows:
a. No applications other than SQL Server, SSMS, and the C# application were active on the test server.
b. SQL Server’s maximum memory limit was set to 12 GB. This allowed SQL to go over its limit without distorting overall system behavior by exhausting server memory entirely.
c. Hot Windows file cache, i.e., a full run that loaded ALL of the flat file data into RAM was performed before the timing tests were run. This insured that the HD was involved minimally.
d. Hot SQL Server buffer cache, achieved by running the next series soon after the last run completed (with no intervening runs), and by running each sequence four times in immediate succession.
The NoStringMax routine cited in #5a in the previous section is shown in Figure 1.
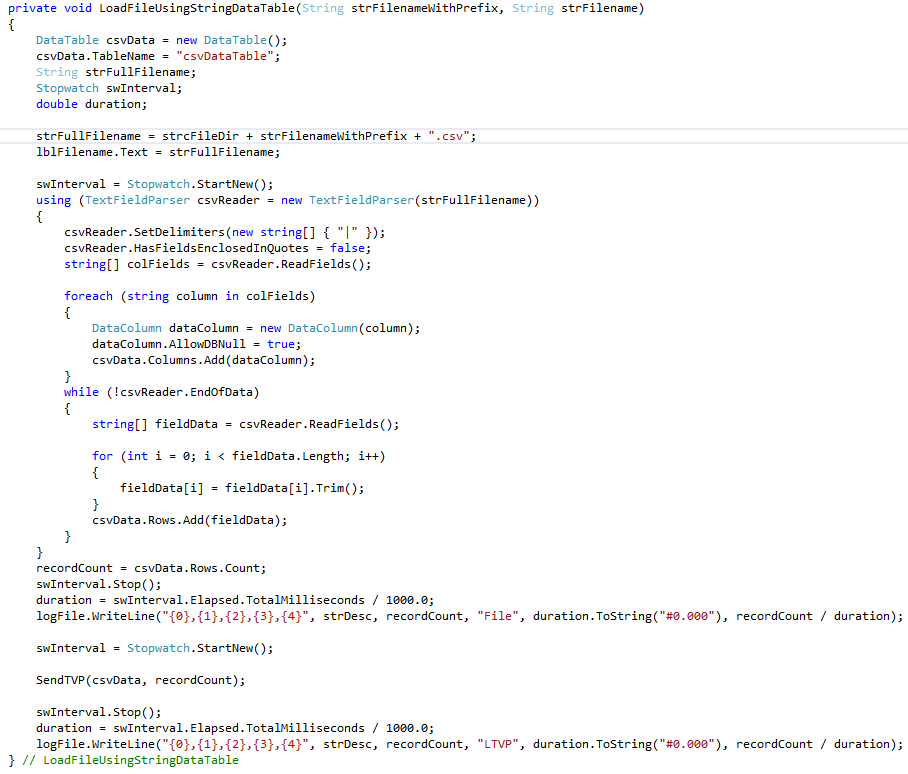
Figure 1: Test C# Data Table Load Routine Using No String Length Maximums
The StringMax routine cited in #5b in the previous section is shown in Figure 2. The ONLY difference between this routine and the previous one is the addition of the MaxLength assignment that is highlighted below. This single line sets the maximum length of each data table column to the value of the iMaxStringLen parameter. As cited in #5b, this value ranged from 30 to 1,000 during testing.
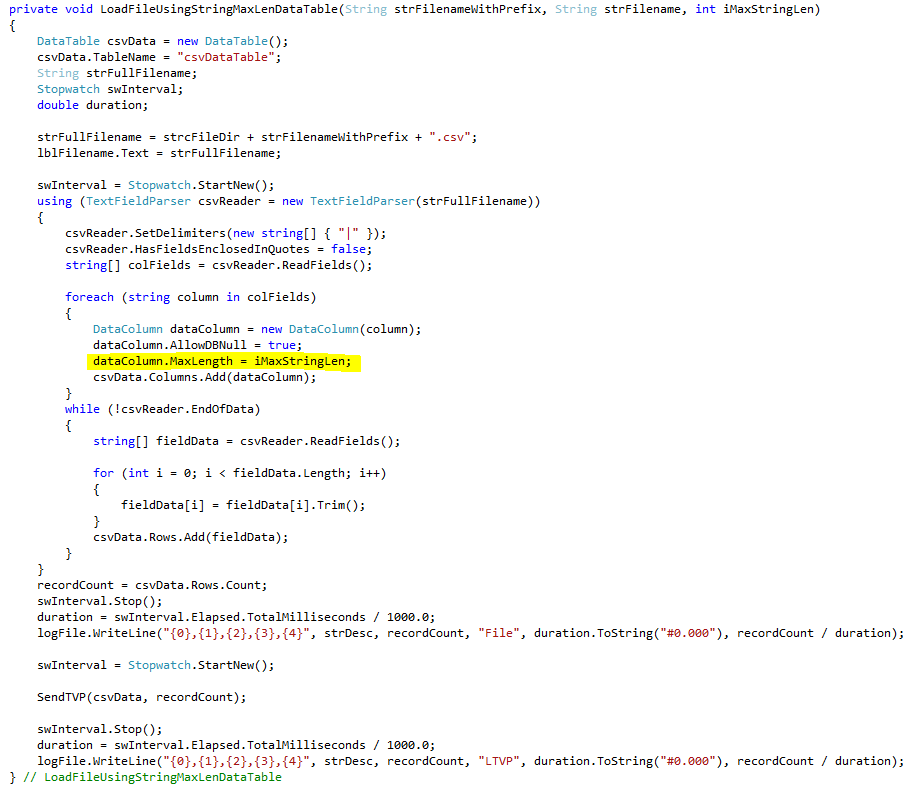
Figure 2: Test C# Data Table Load Routine Using String Length Maximums
The Map routine cited in #5c in the previous section is shown in Figure 3 through Figure 6. Logically, this code is identical to that of #5a and #5b, but the individual column mappings make the routine much longer. Note: since no strings are used for the data table columns, the MaxLength parameter is unnecessary.

Figure 3: Test C# Data Table Load Routine Using Data Type Mapping – Part 1

Figure 4: Test C# Data Table Load Routine Using Data Type Mapping – Part 2
Figure 5: Test C# Data Table Load Routine Using Data Type Mapping – Part 3
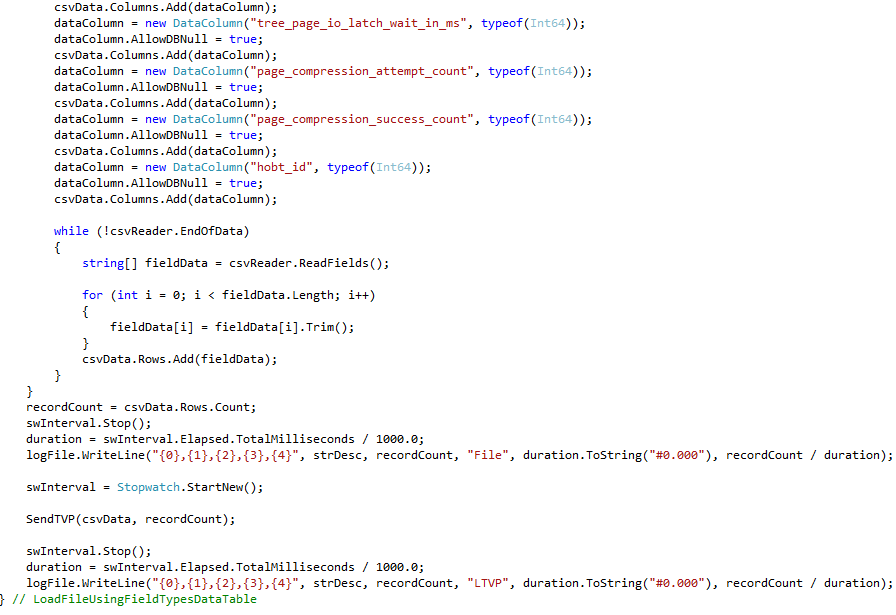
Figure 6: Test C# Data Table Load Routine Using Data Type Mapping – Part 4
The routine cited in #5d in the previous section is shown in Figure 7.
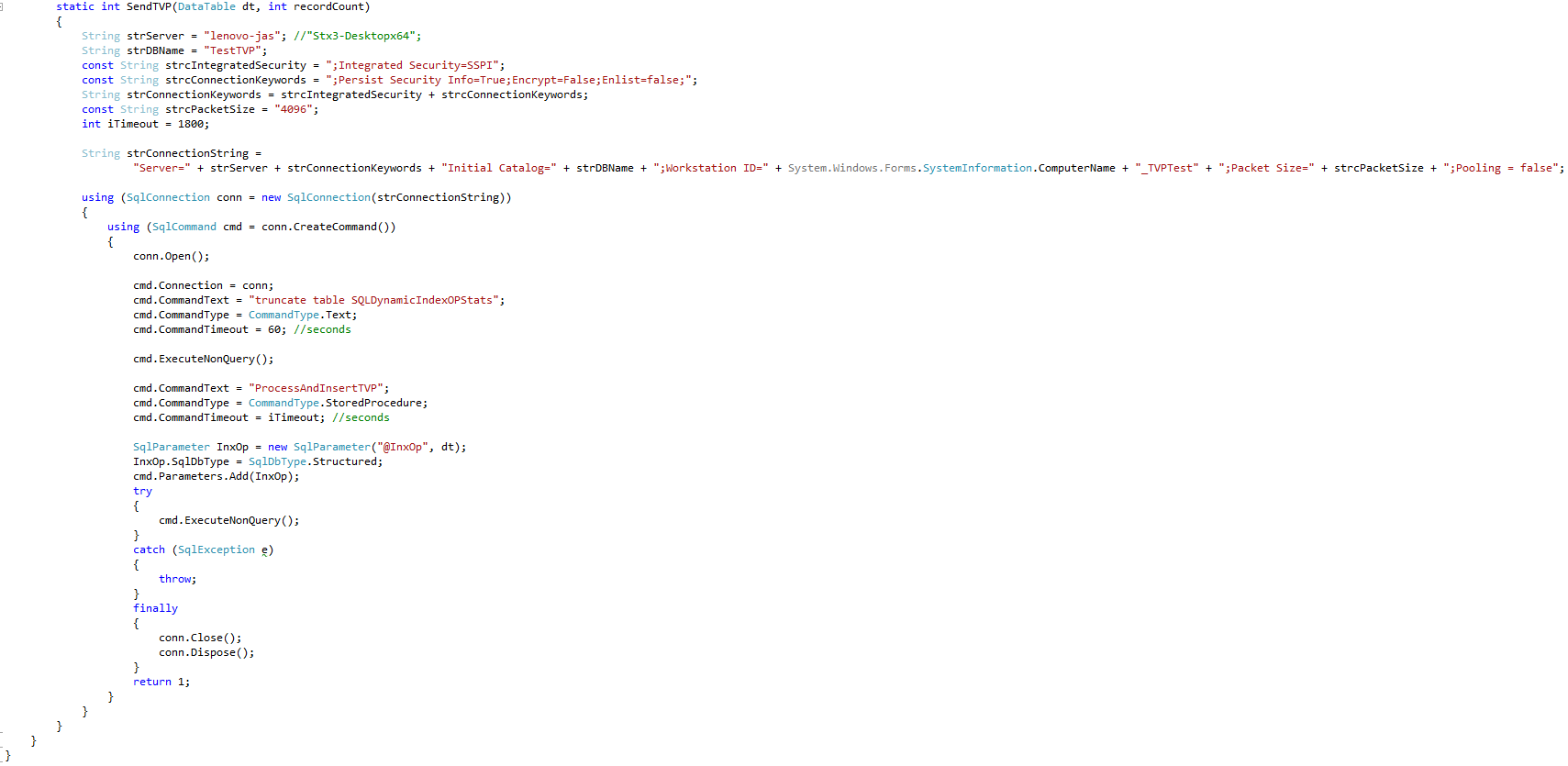
Figure 7: C# Test Routine that Sends Data Table to SQL Server Using a TVP
1.The T-SQL code alone, cited in Test Frameworks #1a did not recreate the problem observed at the customer site when either SQL trace or Extended Events (XEvents) were used, so additional testing was unnecessary.
2.No problems occurred when the C# application was used in conjunction with SQL trace or XEvents as long as no completed events were captured. Therefore, capturing only specific trace events created the problems.
3.Further research showed that when the C# code was running, adding ad-hoc or batch completed events to SQL traces or XEvent sessions caused issues. Adding completed statement events did not change things appreciably.
4.Interestingly, the extreme misbehavior was triggered by the combination of using NoStringMax C# code and having SQL trace or XEvents capture ad-hoc or batch completed events. Although the StringMax and Map routines ran a little more slowly for certain record count levels when SQL trace or XEvents captured ad-hoc or batch completed events, the dramatic memory consumption issues did not occur at all when these methods were used.
5.Initially, testing employed a 28 GB maximum SQL Server memory setting, but as occurred at the customer site, when the problem arose, SQL Server consumed all the memory on the server, which caused the server fundamentally to stop working. Using this setting and the NoStringMax C# code, CSV files with record counts up to 25,000 could be processed without taking hours, failing, or causing the server to run completely out of memory. However, the application could not reach the 50,000 record level.
6.Since testing needed to process MUCH higher numbers of records, the decision was made to reduce SQL Server memory to 4 GB in an attempt to provide additional memory space for SQL Server memory overflow. Another reason for lowering the SQL Server memory allocation was to insure that the tests consumed all of SQL Server’s buffer pool and that SQL Server had to operate against memory limits. This consideration, as well as the run-time variations, necessitated the four successive iterations for each combination.
7.Unfortunately, using the 4 GB setting, the lower-end NoStringMax C# code runs while capturing SQL trace ad-hoc or batch completed events caused application failures at approximately the 4,000 or 8,000 record levels. This clearly indicated an increase in SQL Server memory was required, so it was increased to 8 GB. Although the runs processed more records, they still crashed well before the 25,000 record level. Finally, moving the memory limit up to 12 GB enabled everything to run as before, effectively mimicking the 28 GB testing without running the risk of exhausting Windows memory.
8.Figure 8 highlights the NoStringMax C# code runs through the 25,000 record level while SQL trace or XEvents ad-hoc or batch completed events were being captured. It is evident that the run times were unacceptable. When the same test levels are viewed in Figure 9, the problem becomes abundantly clear. With SQL trace or XEvents capturing ad-hoc or batch completed events, the run times for the 10,000 record tests using the NoStringMax C# code ranged between 483 and 584 seconds. When ad-hoc or batch completed events were not captured, the run times were approximately 0.14 SECONDS! The values for all other tests, including NoStringMax C# code with SQL trace and XEvents ad-hoc or batch completed events off, are shown in Figure 9.
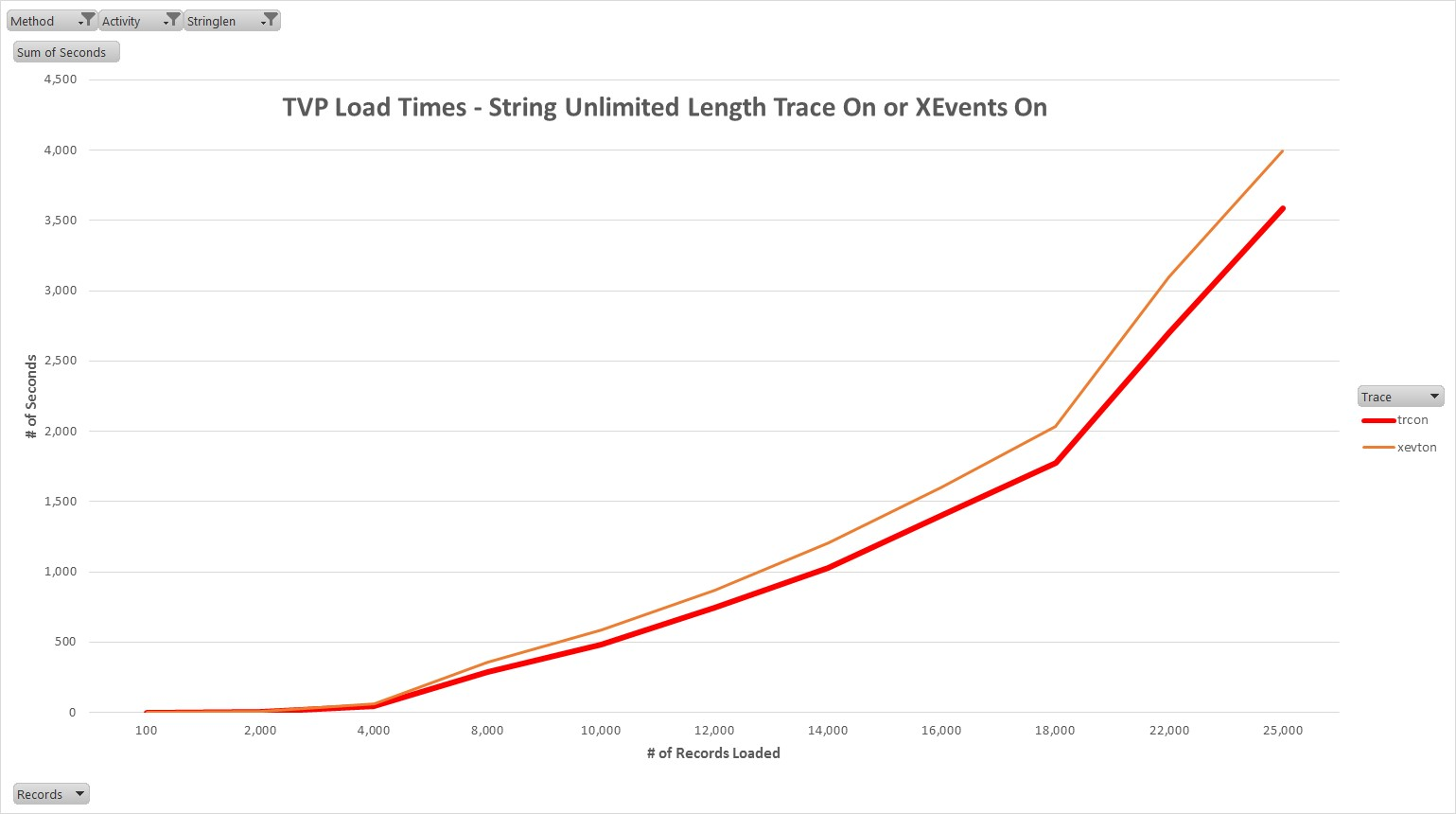
Figure 8: TVP Load Timing when Trace On or XEvents on
9.Although many lines appear in Figure 9, three groupings exist and these are the most important. Group 1, which consists of dotted lines, includes all tests during which ad-hoc or batch completed events were not captured. Group 2, which consists of solid lines, includes all tests during which SQL trace captured ad-hoc or batch completed events. Group 3, which consists of dashed lines, includes all tests during which XEvents captured ad-hoc or batch completed events. Important note: The NoStringMax runs shown in Figure 8 are NOT in Figure 9 because of scaling considerations. Figure 9 highlights several notable issues. Most importantly, once a maximum string length is specified, performance improves even when SQL trace or XEvents ad-hoc or batch completed events are not captured. In addition, the terrible performance problems go away. Interestingly, the behaviors of the various StringMax and Map runs were almost identical through approximately 175,000 records and then again at about 800,000 records. In between, unexplained divergence occurs, but it is only a few seconds and occurred primarily between the 200,000 and 700,000 record levels. The pattern shown in Figure 9 was repeated in every test sequence conducted. It is noteworthy that the StringMax and Map versions of the routine outperformed the NoStringMax under all comparable trace or XEvent-related conditions, and at higher volumes, even when completed events were captured.
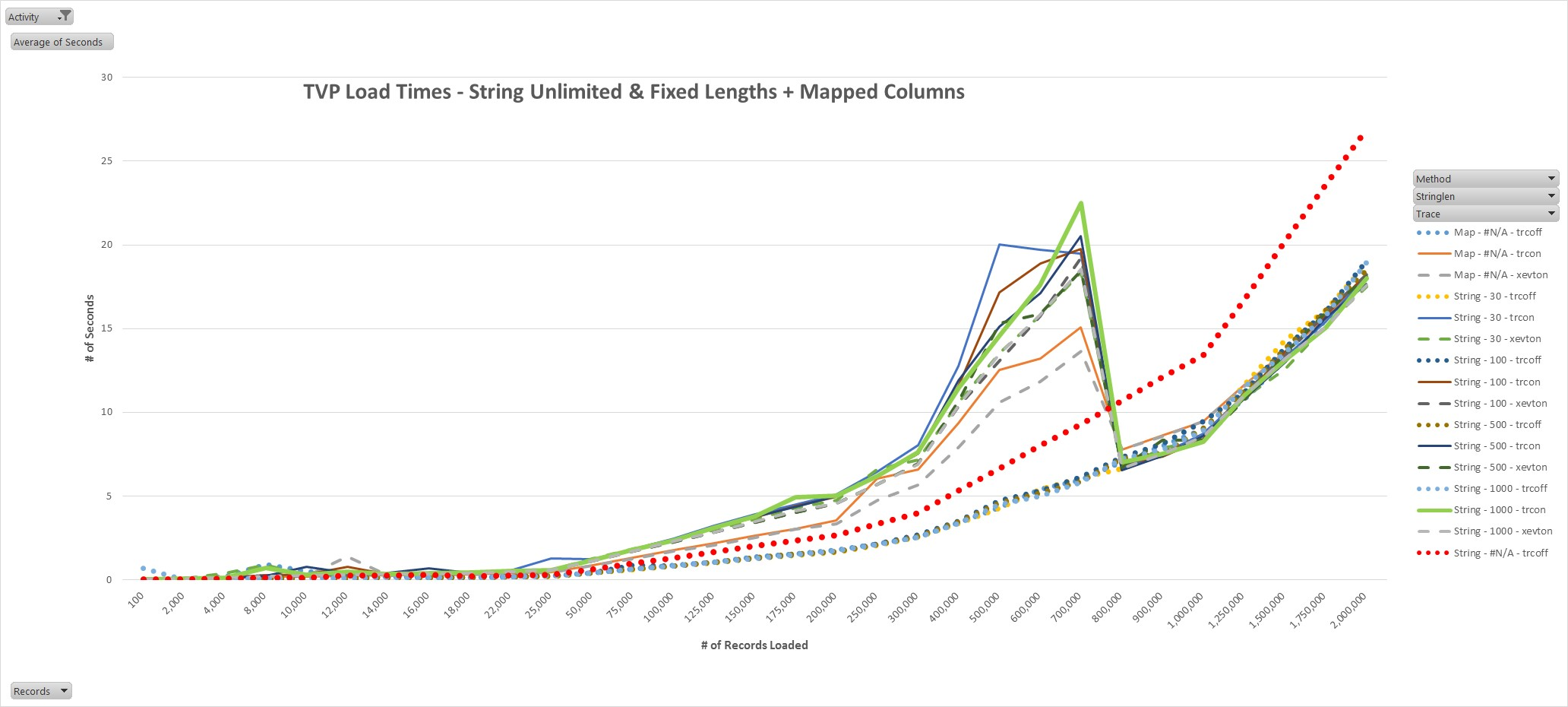
Figure 9: TVP Load Timing when Trace/XEvents off OR Trace or XEvents on and Mapped Data Table or Limited-Length String Values Used
10.Once the number of records exceeeded two million, the load of the C# data table began to crash due to application memory exhaustion. Note: neither Windows nor SQL Server memory was consumed excessively during this phase, so the limitation was strictly application-related.
11.Figure 10 summarizes the overall insertion rates of all previously cited methods at the two million record level, in addition to the bulk insert method. This graph shows clearly that the worst performer was the unlimited string method, and that the best one was the bulk insert method. Note: these rates exclude the reading of the flat file into the C# data table as well as the creation of the file that was suitable for bulk insertion.
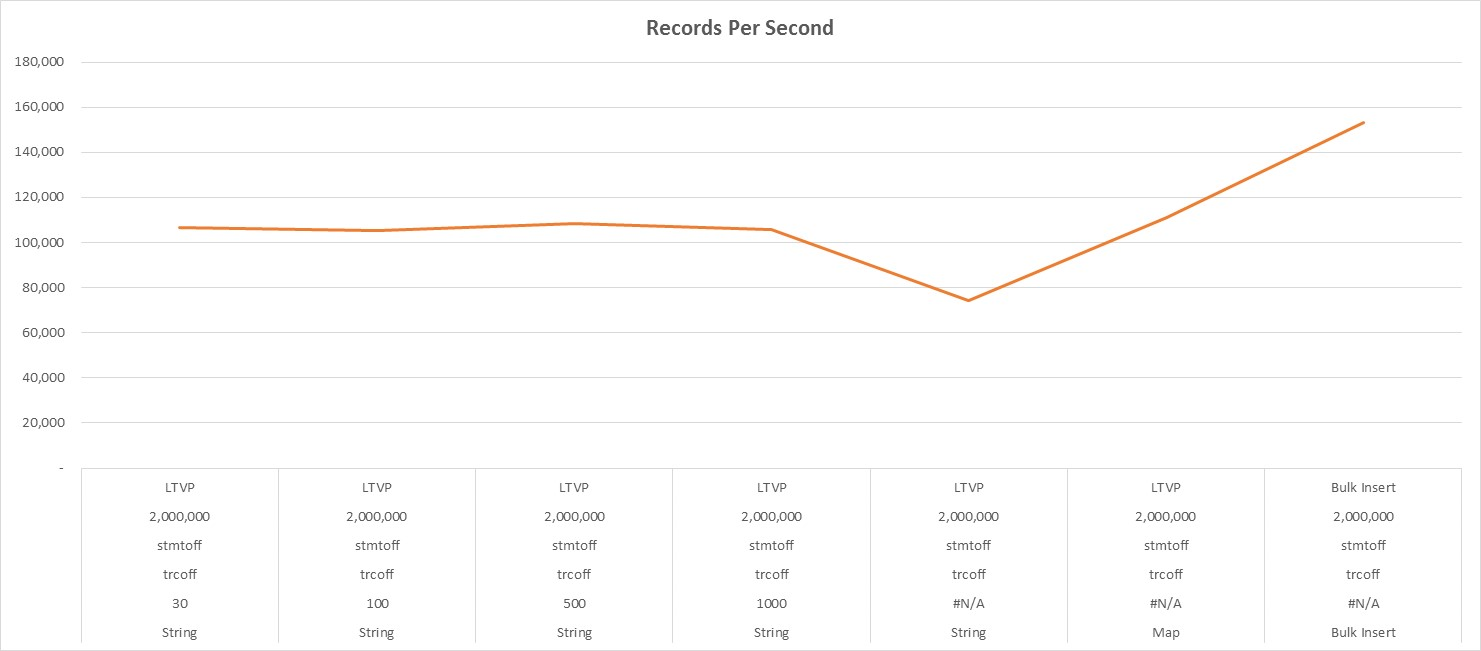
Figure 10: TVP versus Bulk Insert Records per Second
The use of unlimited-length C# strings with data tables not only performs worse without capturing any SQL trace or XEvents ad-hoc or batch completed events, it performs dreadfully when they are. Their use can cause poor overall server performance if the server’s memory is exhausted. Finally, their use prevents the ability to monitor SQL Server query performance using either SQL trace or XEvents. However, when a maximum string length is specified, regardless of its length, performance without SQL trace or XEvents improved and the problematic interaction with SQL trace or XEvents was mitigated almost completely. Since the Map method is inefficient and limiting from an application development perspective and performance was not substantially better than with limited-length strings, its use does not appear to be beneficial.
No table-valued parameter scalability issues were observed with the possible exception of the 200,000 to 700,000 record range when performance inexplicably, and consistently, dipped. However, from 800,000 to 2 million, performance experienced no such dip. Interestingly, standard bulk insert performance exceeded that of TVPs when the same data was used.
Since the code to implement the maximum-length string involves only one line and the performance monitoring and improvement benefits are substantial, the <data table name>.MaxLength = <n> statement should be included in data table load routines as shown by the highlighted line in Figure 2. <n> should be the maximum expected length of any data column. Limiting string length will allow C# TVP data loads to run more efficiently and also enable customers to conduct normal query performance monitoring.
********************************************
The code shown in this post can be downloaded from here…. SQLRX_TVP_CSharp_Code
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. Visit us at www.sqlrx.com!