Menu
–by Ginger Keys
AlwaysOn Availability Groups is a great new feature of SQL 2012 and 2014. This feature is a combination of database mirroring and failover clustering, and it provides a strong level of high availability and disaster recovery; however there is no straightforward monitoring/alerting processes to go along with this new functionality.
It is important for you to 1) observe the current state and health of your Availability Group, but more importantly 2) get alerted if things go wrong.
You need to know if your AG is healthy, online, synchronizing, and available. And you might need to keep track of issues with failover, and the overall health of the servers and the Availability Group.
There are a few different methods to monitor your system, and also to alert you to problems. I have tried to piece together a broad approach to monitoring/alerting. These methods can be configured and altered to include more, less, or different data, depending upon your specific needs for your organization and system. But this is a good starting point for you to begin with, and alter if needed.
SSMS Availability Group Dashboard –
The first method you can use to observe the state of your AlwaysOn Availability Group is the AlwaysOn Dashboard.
Below is the AlwaysOn Availability Group I have created:
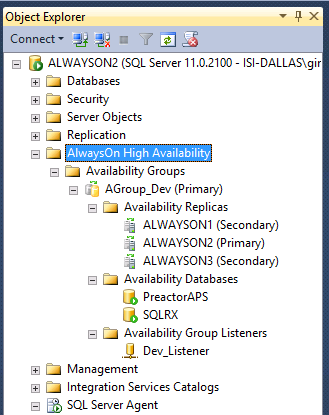
SQL Management Studio (SSMS) provides a Dashboard tool to monitor the current state and health of your Availability Groups (AG). Simply right click on the Availability Groups folder in Object Explorer, and select “Show Dashboard” to get an overview of the state of your AG.
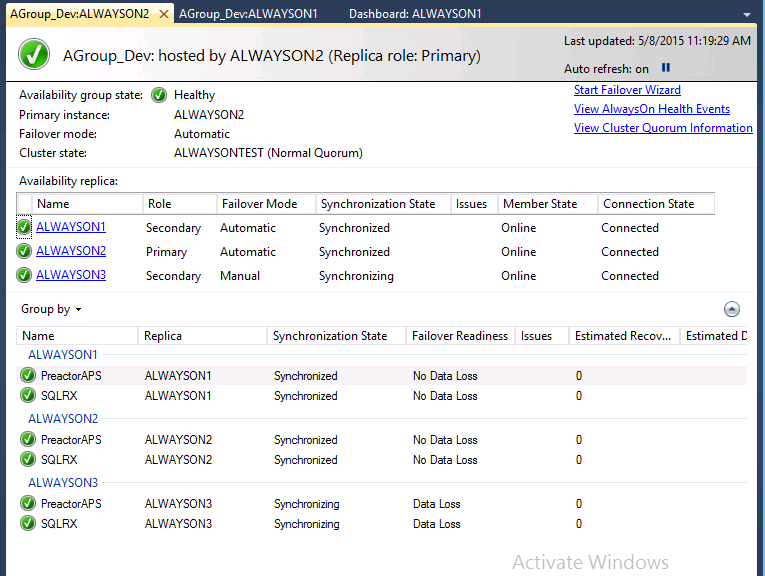
In this Dashboard, you can see which replicas are primary/secondary, the databases in the AG, the failover mode, and if they are online and connected to the AG. If there are any issues, a link will appear in the Issues column which will help you troubleshoot.
The synchronization state column indicates the method of data replication – if the state is ‘synchronized’ that means that the data is replicating synchronously to the secondary replica (the primary waits for secondary to harden the log before moving on to the next task). If the state is ‘synchronizing’, that means the data is replicating asynchronously, so the primary replica is not waiting for the secondary to harden the log, and there could be possible data loss.
Notice in my dashboard above, I have included the columns Estimated Data Loss and Estimated Recovery Time. These two measures are not included in the default view, but you can add the additional columns by right clicking on the column heading and choosing additional columns to include. Estimated Data Loss tell us the time difference of the last transaction log record in the primary replica and secondary replica. If the primary replica fails, the transaction log records in that time window will be lost. The Estimated Recovery Time tells us the time in seconds it takes to redo the catch-up time. The catch-up time is the time it will take for the secondary replica to harden the logs and catch up with the primary replica. For organizations that are highly transaction sensitive and have no tolerance for data loss, these are important metrics to keep an eye on.
The AG Dashboard in SSMS will not notify you of problems…you will only see problems through AG Dashboard if you happen to be looking at the dashboard at the exact time a problem occurs. This tool is only beneficial for seeing the current state and health of your AlwaysOn Group.
The AlwaysOn Dashboard is easy to use and very intuitive. It queries several DMVs and produces a nice, easy-to-read report for you to see the current state of your AlwaysOn Group. However, producing this nice report can create a performance hit on your server.
If you want to gather information about the current health of your Availability Group directly through DMVs instead of opening the Dashboard, you can run the following script to derive roughly the same information:
select cluster_name,
quorum_state_desc
from sys.dm_hadr_cluster
GO
select ar.replica_server_name,
ars.role_desc,
ar.failover_mode_desc,
ars.synchronization_health_desc,
ars.operational_state_desc,
CASE ars.connected_state
WHEN 0 THEN ‘Disconnected’
WHEN 1 THEN ‘Connected’
ELSE ”
END as ConnectionState
from sys.dm_hadr_availability_replica_states ars
inner join sys.availability_replicas ar on ars.replica_id = ar.replica_id
and ars.group_id = ar.group_id
GO
select distinct rcs.database_name,
ar.replica_server_name,
drs.synchronization_state_desc,
drs.synchronization_health_desc,
CASE rcs.is_failover_ready
WHEN 0 THEN ‘Data Loss’
WHEN 1 THEN ‘No Data Loss’
ELSE ”
END as FailoverReady
from sys.dm_hadr_database_replica_states drs
inner join sys.availability_replicas ar on drs.replica_id = ar.replica_id
and drs.group_id = ar.group_id
inner join sys.dm_hadr_database_replica_cluster_states rcs on drs.replica_id = rcs.replica_id
order by replica_server_name
Dynamic Management Views –
The second method you can use to observe the current state of your AlwaysOn Availability Groups is through querying dynamic management views (DMVs). SQL provides several DMVs to monitor the state of your AlwaysOn Availability Group that will give you information about your AG cluster, networks, replicas, databases, and listeners.
sys.dm_hadr_cluster
sys.dm_hadr_cluster_members
sys.dm_hadr_cluster_networks
sys.availability_groups
sys.availability_groups_cluster
sys.dm_hadr_availability_group_states
sys.availability_replicas
sys.dm_hadr_availability_replica_cluster_nodes
sys.dm_hadr_availability_replica_cluster_states
sys.dm_hadr_availability_replica_states
sys.dm_hadr_auto_page_repair
sys.dm_hadr_database_replica_states
sys.dm_hadr_database_replica_cluster_states
sys.availability_group_listener_ip_addresses
sys.availability_group_listeners
sys.dm_tcp_listener_states
These DMVs are all explained here https://msdn.microsoft.com/en-us/library/ff878305%28SQL.110%29.aspx . You can query any of these DMVs to gather information about your AG such as configuration, health status, and the condition of your Availability Group. Another great link for further explanation of these DMVs is here https://msdn.microsoft.com/en-us/library/ff877943.aspx?f=255&MSPPError=-2147217396 .
Just an FYI…AlwaysOn AG catalog views require View Any Definition permission on the server instance. AlwaysOn Availability Groups dynamic management views require View Server State permission on the server.
SQL Server Agent Alerts
The best method for creating alerts for your AG that will notify you as soon as any problem or event occurs, is the SQL Server Agent Alerts. These alerts are a great way to be proactive in monitoring your AG, and there are several alerts specifically related to AlwaysOn Availability Groups. In order to find which error codes correspond to an AG event you can run this query:
use master
go
select message_id as ErrorNumber, text
from sys.messages
where text LIKE (‘%availability%’)
and language_id = 1033
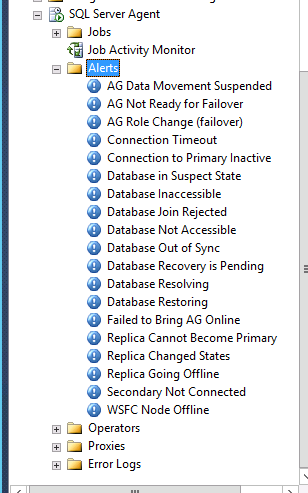
This will give you a result set with 293 rows. You can peruse through and determine which errors are important for you, but I have devised a list with what we feel is the most important information to be alerted on:
Errors:
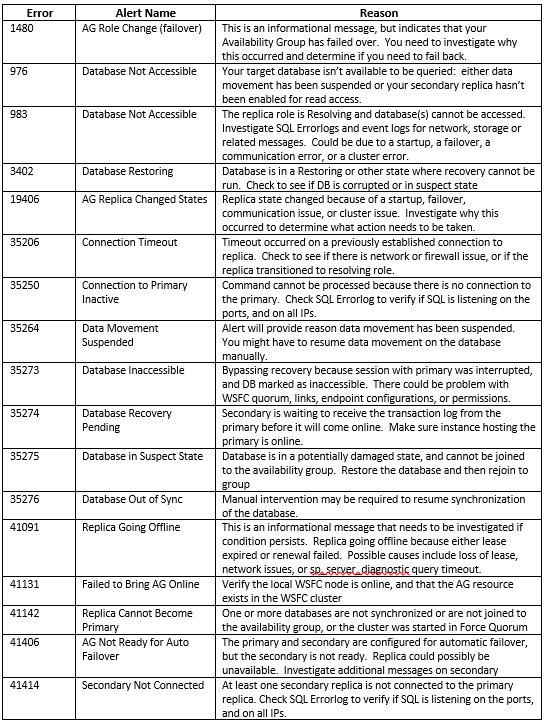
In order to create a SQL Server Agent Alert, you must have the Database Mail configured and enabled, and you must have an Operator created. For instructions on how to do this click here: https://msdn.microsoft.com/en-us/ms186358.aspx
You can create your alerts using TSQL by executing the following script, and substituting the Name of Alert and Operator that is applicable to your environment:
— 1480 – AG Role Change (failover)
EXEC msdb.dbo.sp_add_alert
@name = N'[Name of Alert]’,
@message_id = 1480,
@severity = 0,
@enabled = 1,
@delay_between_responses = 0,
@include_event_description_in = 1;
GO
EXEC msdb.dbo.sp_add_notification
@alert_name = N'[Name of Alert]’,
@operator_name = N'[Operator]’,
@notification_method = 1;
GO
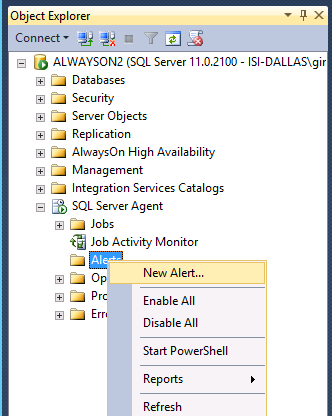
Or you can create your alerts using the New Alert Wizard. In SSMS, expand the SQL Server Agent, and right click on Alerts. Select New Alert:
Create a name for your Alert, specify the Error Number, and make sure the alert is Enabled:
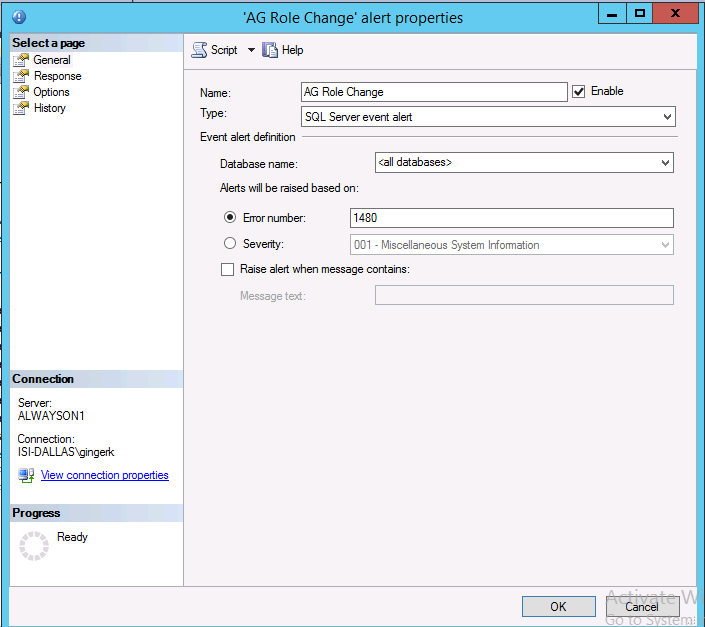
On the Responses page of the alert properties, specify the operator(s) you created earlier to receive the alerts:
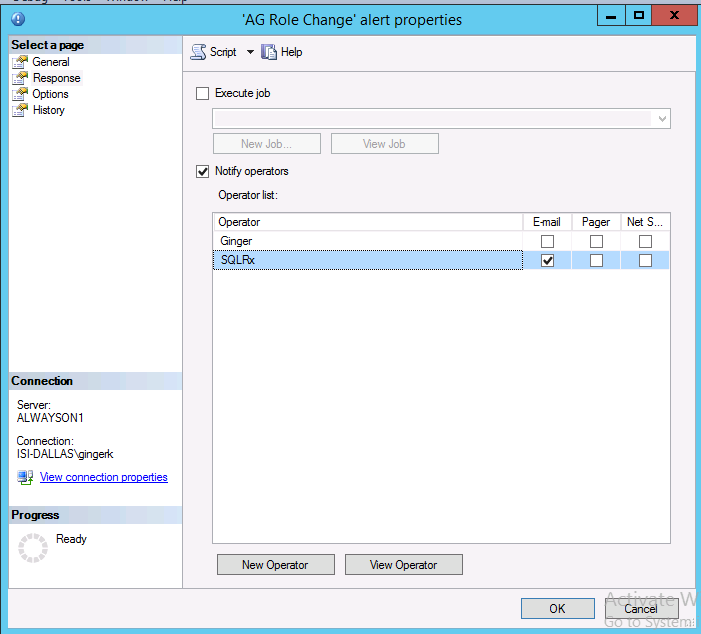
On the Options page of the alert properties, specify how (or if) you would like to receive the alert error message text (email, pager, net send).
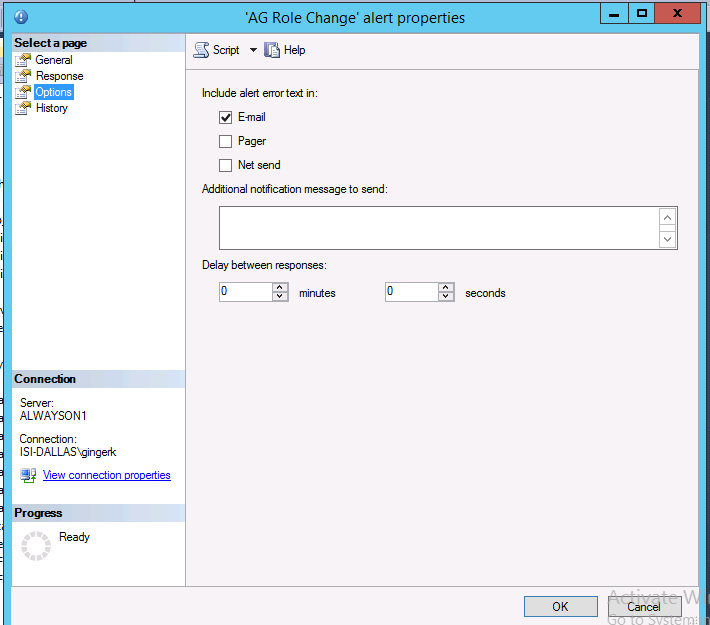
Be sure to create these alerts on each of your replicas.
Conclusion
It’s certainly important to be able to observe the current state of your AlwaysOn Availability Group, and it’s even more important to be notified when an issue occurs that requires your attention. The methods outlined above provide a comprehensive approach, allowing you to be proactive to ensure your system is healthy.
If you would like assistance monitoring your AlwaysOn Group, or your SQL Servers and databases, please contact us at SQLRxSupport@sqlrx.com or SQLRx@isi85.com . We would be happy to answer any question you have, and would be interested to hear about your experiences with AlwaysOn!
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRxSupport@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. We love to talk tech with anyone in our SQL family!
Session expired
Please log in again. The login page will open in a new tab. After logging in you can close it and return to this page.
[…] reading up on AlwaysOn Monitoring and Alerting (http://blog.sqlrx.com/2015/08/27/alwayson-monitoring-and-alerting/), I was asked to come up with a way to automatically enable jobs that may only need to run on the […]
HI
I tried the above and it did not work, i suspended data movement to see if i would get an alert and nothing.