Menu
Find and Remove Duplicate Records
By Ginger Daniel | Beginner
— by Ginger Keys
Having duplicate records in a database is an age-old problem that almost every organization has to deal with. Duplicates can appear because of careless data input, merging records from old systems into new systems, uploading leads from purchased lists, and multiple other reasons.
Identifying these duplicate records can also be tricky. You might have multiple people with the same first and last name. You might have one person with multiple addresses, emails, or other identifying characteristics. In most cases business rules, not repetitive values, will determine what constitutes duplicate data. Knowing your data is the key to determining whether your records are duplicates or not.
It can be a painstaking process, but we will go over some basic steps to help find and remove duplicate records in your database.
Create Duplicates
First let’s take a look at a table and purposefully insert duplicate records into it. I have selected rows out of a table that contains customer information.
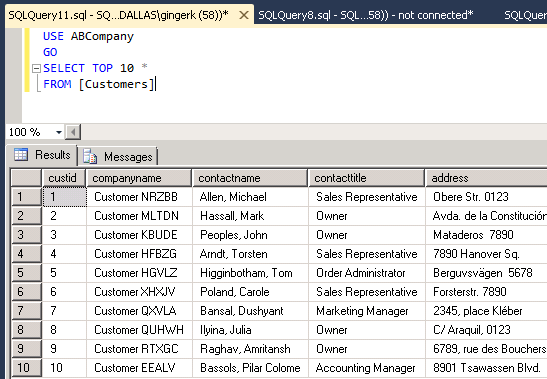
Now I will insert these rows of data into my Customers table to create duplicate rows:
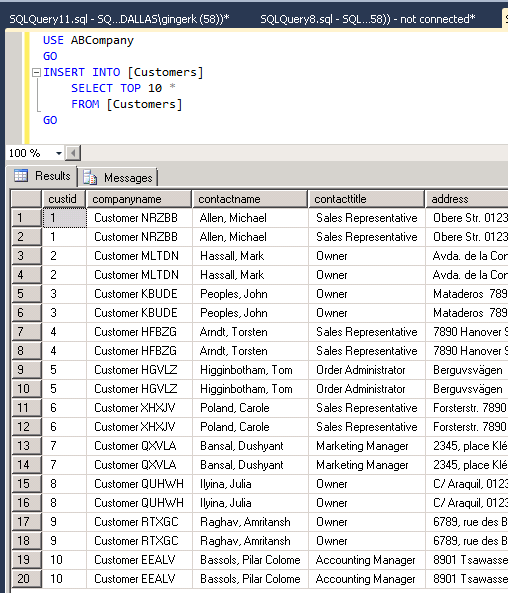
Find Duplicates
Duplicate records in your table will most likely not be in sequential order, as shown in our example above. So in order to find duplicates in your table run this query, substituting the names of your database, table, and relevant columns. You will need to determine which field(s) in your table will constitute duplicate records. Again, knowing your data and business rules for your organization will determine whether you have duplicate records in your database.
USE YourDatabase
GO
SELECT column1, column2, COUNT(column2) AS Duplicates
FROM YourTable
GROUP BY column1, column2
HAVING COUNT(column2) > 1
In our example below, the results below assume that contactname is the column we are using to determine duplicate records in our table.
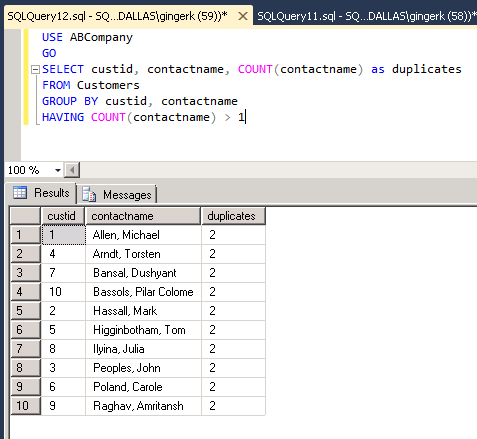
Delete Duplicates
Now that we see there are indeed duplicate records in our table, we can delete duplicate rows with this script (again, you will substitute your database, table, and column names):
SET NOCOUNT ON
SET ROWCOUNT 1
WHILE 1 = 1
BEGIN
DELETE
FROM Customers
WHERE contactname IN
(SELECT contactname
FROM Customers
GROUP BY contactname
HAVING COUNT(*) > 1)
IF @@Rowcount = 0
BREAK ;
END
SET ROWCOUNT 0
To check the results, we run the select statement again to make sure the duplicates are gone:
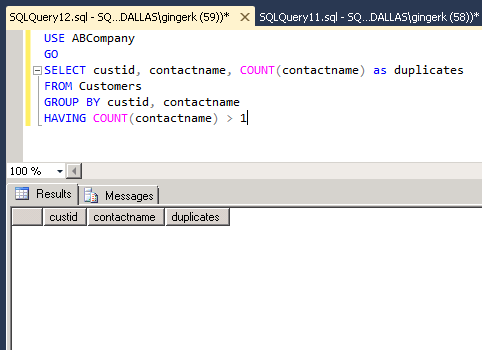
Conclusion
SQL Server has methods for preventing duplicate records in a database, such as enforcing entity integrity through the use of primary key constraints, unique key constraints, and triggers. However duplicates can occasionally occur because of database design error, or repetitive data that somehow gets past these quality control methods. The techniques described above, in addition to your familiarity with your data, will help you to find and delete duplicate records in your databases.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRX@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. We love to talk tech with anyone in our SQL family!
Session expired
Please log in again. The login page will open in a new tab. After logging in you can close it and return to this page.
while(1=1)
begin delete top (1) from c1
FROM Customer c1
INNER JOIN (SELECT Custid, ContactName from Customer group by Custid, ContactName having count(1) > 1) c2 ON c1.Custid = c2.Custid and c1.ContactName = c2.ContactName
if @@rowcount = 0
break;
end
Good alternative script for deleting duplicate rows…thanks, Krushna!