Menu
I occasionally come across some pretty good sized databases that are set up with a single data file. We recently have been working with a client to break up their single data file into multiple data files so that we can spread them over several different LUNs and so that they can take advantage of the improved performance of using the files in parallel. The concept is much like setting up tempdb with 1 file (up to 8) per core.
Since most people don’t think about using multiple files for databases until they have grown large enough to be a problem, I think that most don’t realize that breaking up a database can be done at any time, you just need to have enough space for new files. Here is a bit of a demo on how to do this.
Create a database with one file and load it with a couple of large tables
USE [master] GO CREATE DATABASE [ADMIN] ON PRIMARY ( NAME = N'ADMIN', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\ADMIN.mdf' , SIZE = 102400KB , FILEGROWTH = 102400KB ) LOG ON ( NAME = N'ADMIN_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\ADMIN_log.ldf' , SIZE = 102400KB , FILEGROWTH = 102400KB ) GO ALTER DATABASE [ADMIN] MODIFY FILE ( NAME = N'ADMIN', SIZE = 409600KB ) GO
-- ********************************************
-- Use the below code to load random data into tables
-- Change the value in the WHILE @Loop to control how many records are created
-- ********************************************
USE ADMIN
GO
CREATE TABLE [dbo].[RandomLoad1](
[NumberColumn] [int] NULL,
[BitColumn] [bit] NULL,
[VarcharColumn] [varchar](20) NULL,
[VarcharColumn100] [varchar](100) NULL,
[CharColumn] [char](1) NULL,
[DateColumn] [date] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[RandomLoad2](
[NumberColumn] [int] NULL,
[BitColumn] [bit] NULL,
[VarcharColumn] [varchar](20) NULL,
[VarcharColumn100] [varchar](100) NULL,
[CharColumn] [char](1) NULL,
[DateColumn] [date] NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[RandomLoad3](
[NumberColumn] [int] NULL,
[BitColumn] [bit] NULL,
[VarcharColumn] [varchar](20) NULL,
[VarcharColumn100] [varchar](100) NULL,
[CharColumn] [char](1) NULL,
[DateColumn] [date] NULL
) ON [PRIMARY]
GO
-- This will populate a table with random records
DECLARE @Loop INT
DECLARE @varchar1 VARCHAR(20)
DECLARE @varchar2 VARCHAR(100)
DECLARE @varbin1 VARBINARY(128)
DECLARE @Char1 CHAR(2)
DECLARE @Num1 INT
DECLARE @Bit1 BIT
DECLARE @Date1 DATE
DECLARE @length INT
SET @Loop = 0
WHILE @Loop < 1000000 -- number of records to generate 5000 10000 500000 1000000
BEGIN
-- Generate Number
SET @Num1 = ROUND(RAND() * 100000, 0)
-- Generate Bit
SET @Bit1 = CRYPT_GEN_RANDOM(1)%2
-- Generate Varchar
SET @varchar1 = ''
SET @length = CAST(RAND() * 20 AS INT)
WHILE @length <> 0
BEGIN
SET @varchar1 = @varchar1 + CHAR(CAST(RAND() * 96 + 32 AS INT))
SET @length = @length - 1
END
-- Generate Varchar 100
SET @varchar2 = ''
SET @length = CAST(RAND() * 100 AS INT)
WHILE @length <> 0
BEGIN
SET @varchar2 = @varchar2 + CHAR(CAST(RAND() * 96 + 50 AS INT))
SET @length = @length - 1
END
-- Generate Char
SET @Char1 = LEFT(newid(),1)
-- Generate Date
SET @Date1 = CAST(GETDATE() + (365 * 2 * RAND() - 365) AS DATE)
INSERT INTO [RandomLoad1] VALUES (@Num1,@Bit1,@varchar1,@varchar2,@Char1,@Date1)
SET @Loop = @Loop + 1
END
GO
As you load data you can seed some known values into the tables at different places while loading up the tables with random values. This will let you run some test queries if you are interested in them.
INSERT INTO RandomLoad1 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (1001, 1, 'U2', 'And I still haven''t found what I''m looking for.', 'A', '2017-05-21') INSERT INTO RandomLoad1 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (2001, 0, 'ZZ Top', 'Cause every girl''s crazy bout a sharp dressed man.', 'B', '2015-11-11') INSERT INTO RandomLoad1 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (3001, 1, 'Cyndi Lauper', 'Girls just wanna have fun!', 'C', '2012-08-08') INSERT INTO RandomLoad1 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (4001, 1, 'Def Leppard', 'Rock of ages, still a rollin!', 'D', '2018-10-15') INSERT INTO RandomLoad2 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (5001, 1, 'Flock of Seagulls', 'I just ran. I ran so far away.', 'E', '1984-02-14') INSERT INTO RandomLoad2 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (6001, 0, 'Styx', 'Domo Arigato Mister Roboto!', 'F', '1999-12-31') INSERT INTO RandomLoad3 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (7001, 1, 'Huey Lewis&the News', 'They say the heart of rock n roll is still beating.', 'G', '2003-06-02') INSERT INTO RandomLoad3 ([NumberColumn],[BitColumn],[VarcharColumn],[VarcharColumn100],[CharColumn],[DateColumn]) VALUES (8001, 0, 'Twisted Sister', 'We''re not gonna take it anymore!', 'H', '2008-03-05')
Here is how the single database file is filled.
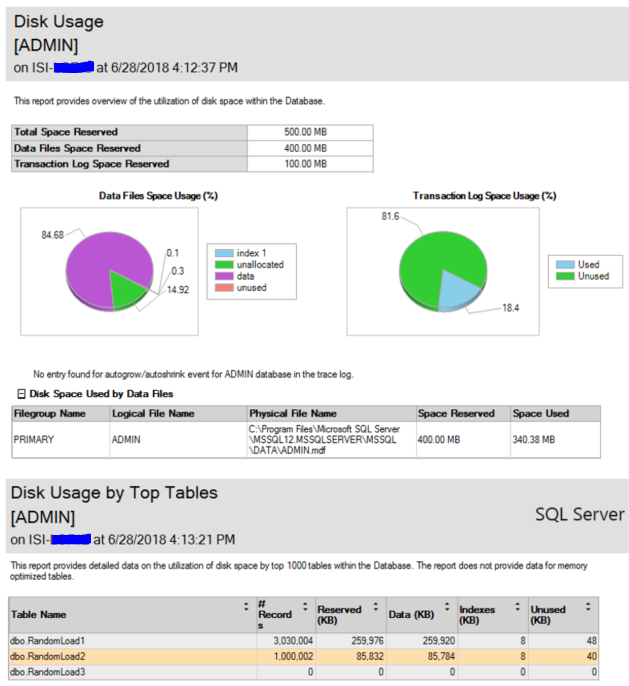
Now I want to add more files to break the main .mdf up so that I can spread the files around and take advantage of some nice performance.
Add 3 new files…
-- Add files. You can either add a new filegroup and new files or simply add files to an existing filegroup USE [master] GO ALTER DATABASE [ADMIN] ADD FILE ( NAME = N'ADMIN2', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\ADMIN2.ndf' , SIZE = 204800KB , FILEGROWTH = 102400KB) TO FILEGROUP [PRIMARY] GO ALTER DATABASE [ADMIN] ADD FILE ( NAME = N'ADMIN3', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\ADMIN3.ndf' , SIZE = 204800KB , FILEGROWTH = 102400KB) TO FILEGROUP [PRIMARY] GO ALTER DATABASE [ADMIN] ADD FILE ( NAME = N'ADMIN4', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\ADMIN4.ndf' , SIZE = 204800KB , FILEGROWTH = 102400KB) TO FILEGROUP [PRIMARY] GO
Here is how space is used in them before moving data to the new files.
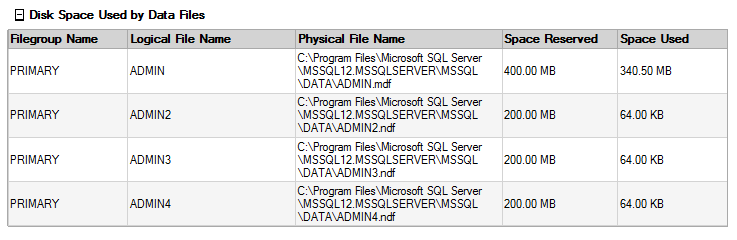
Now we run a DBCC SHRINKFILE with EMPTYFILE and it will automatically start distributing data to the new files.
--Distribute the primary database .mdf file and empty it USE [ADMIN] GO DBCC SHRINKFILE (N'ADMIN', EMPTYFILE) GO
This will actually run in the background so if your workload is light, you can run it while users are connected. Otherwise you will need to do this during a maintenance window when use is light or none at all. You can also stop and restart this process. So, if you can only let this go for 5 hours on one day and have to work on it again on another day you can do that but just stopping the above query and starting up again later.

I ran into this error at the end of the shrinkfile. This happens because there is still system info in the first file that cannot be moved and is expected behavior. Here is how the files are filled after the shrinkfile. You can see that the new files have data sort of evenly distributed to them.
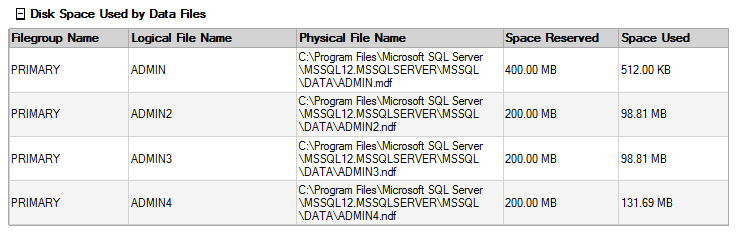
I decided to shrink the original database file to match the size of the other files so that I would not see any strange usage with one file being larger than all the others. It is important to try to keep them all the same size.
GO DBCC SHRINKFILE (N'ADMIN', 200) GO
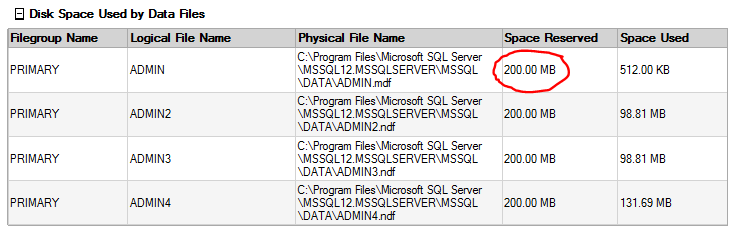
Now, I loaded more random data to see how the data will be stored. You can see the proportional fill is working.
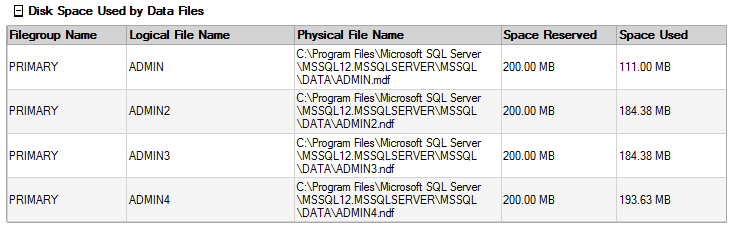
I have actually performed this type of project a couple of years ago on a live database that was roughly 1TB. It took several days and did cause the users to experience some slowness. So, test things well so that you can know what to expect if you break up your database.
If you are wondering about how performance will be improved, check out this from Paul Randal ( Blog | Twitter ). The post while a little old is still very good. https://www.sqlskills.com/blogs/paul/benchmarking-do-multiple-data-files-make-a-difference/
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. We love to talk tech with anyone in our SQL family!
Session expired
Please log in again. The login page will open in a new tab. After logging in you can close it and return to this page.
[…] Lori Brown shows us how to take a database with one database file and add new database files to it: […]