Menu
Have you ever had transactional replication mysteriously start showing significant latency at a subscriber server? If so, check to see if the primary keys from the publisher database are missing on the subscriber database!
Replication was showing long latency while the publisher and subscriber servers were not heavily utilized. Microsoft generated stored procedures that are used to send INSERT, UPDATE and DELETE operations from the publisher database to the subscriber database had no indexes to help query performance to the subscriber tables. Since there were no indexes that matched the keys of the statements pushing through data changes, tables were being fully scanned and replication statements were piling up. In other words, the subscriber was missing indexes.
I made sure at the publisher that replicated tables were configured with copy clustered primary key index = true but many clustered primary key indexes were still not created on the subscriber tables. I also checked that a new snapshot had been taken recently and found that had been done as well. Replication should be creating the clustered primary key indexes of all tables involved in our publication in this case, but it is obviously not, and it is not consistent about it either. Some tables had the clustered primary key and some did not. Regardless, replication stored procedures need those clustered primary key indexes to perform well.
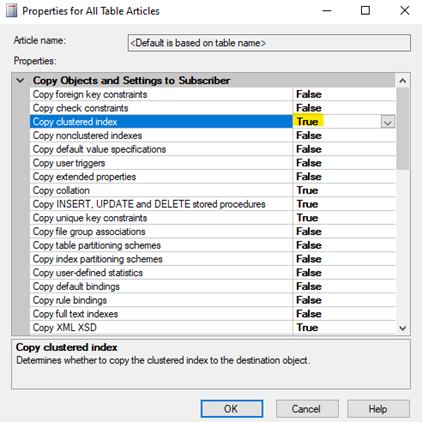
Create a workaround to make the much-needed clustered primary key indexes available on the subscriber database tables. Create a job to run once a day on the subscriber server that would contain code that would create clustered primary key indexes on all subscriber tables exactly as they are on the publisher tables. Optimally, that code would check to see if the index currently exists and if not then create the index. If the index already exists, then the index would not be created. Admittedly this is a little heavy handed, but it bypasses the strange clustered primary key index creation inconsistency with replication.
Of course, I needed to find a way to script out the clustered primary key indexes from the replicated tables in the publisher first. I found this nice post from Percy Reyes at MSSQLTips that was very helpful. Script Constraints, Primary and Foreign Keys for SQL Server Database (mssqltips.com)
I made a few small tweaks to
1) only script the primary key indexes,
2) I also joined the CursorIndex cursor to the sysarticles table to only script tables that are replicated and
3) added the check for the existence of the index using “IF EXISTS” into the @TSQLScripCreationIndex string and had exactly what I needed.
My changes are commented so hopefully readers can follow along.
USE <<Publisher Database>>
--- GENERATE THE CREATION SCRIPT OF ALL PKs on tables that are being replicated.
--- Original author Percy Reyes
--- https://www.mssqltips.com/sqlservertip/3443/script-all-primary-keys-unique-constraints-and-foreign-keys-in-a-sql-server-database-using-tsql/
declare @SchemaName varchar(100)
declare @TableName varchar(256)
declare @IndexName varchar(256)
declare @ColumnName varchar(100)
declare @is_unique_constraint varchar(100)
declare @IndexTypeDesc varchar(100)
declare @FileGroupName varchar(100)
declare @is_disabled varchar(100)
declare @IndexOptions varchar(max)
declare @IndexColumnId int
declare @IsDescendingKey int
declare @IsIncludedColumn int
declare @TSQLScripCreationIndex varchar(max)
declare @TSQLScripDisableIndex varchar(max)
declare @is_primary_key varchar(100)
declare CursorIndex cursor for
select schema_name(t.schema_id) [schema_name], t.name, ix.name,
case when ix.is_unique_constraint = 1 then ' UNIQUE ' else '' END
,case when ix.is_primary_key = 1 then ' PRIMARY KEY ' else '' END
, ix.type_desc,
case when ix.is_padded=1 then 'PAD_INDEX = ON, ' else 'PAD_INDEX = OFF, ' end
+ case when ix.allow_page_locks=1 then 'ALLOW_PAGE_LOCKS = ON, ' else 'ALLOW_PAGE_LOCKS = OFF, ' end
+ case when ix.allow_row_locks=1 then 'ALLOW_ROW_LOCKS = ON, ' else 'ALLOW_ROW_LOCKS = OFF, ' end
+ case when INDEXPROPERTY(t.object_id, ix.name, 'IsStatistics') = 1 then 'STATISTICS_NORECOMPUTE = ON, ' else 'STATISTICS_NORECOMPUTE = OFF, ' end
+ case when ix.ignore_dup_key=1 then 'IGNORE_DUP_KEY = ON, ' else 'IGNORE_DUP_KEY = OFF, ' end
+ 'SORT_IN_TEMPDB = OFF, FILLFACTOR =' + CAST(ix.fill_factor AS VARCHAR(3)) AS IndexOptions
, FILEGROUP_NAME(ix.data_space_id) FileGroupName
from sys.tables t
inner join sys.indexes ix on t.object_id=ix.object_id
where ix.type>0 and ix.is_primary_key=1 -- get primary keys only
and t.is_ms_shipped=0 and t.name<>'sysdiagrams'
and t.name in (select name from sysarticles) -- only get indexes for tables that are being replicated
order by schema_name(t.schema_id), t.name, ix.name
open CursorIndex
fetch next from CursorIndex into @SchemaName, @TableName, @IndexName, @is_unique_constraint, @is_primary_key, @IndexTypeDesc, @IndexOptions, @FileGroupName
while (@@fetch_status=0)
begin
declare @IndexColumns varchar(max)
declare @IncludedColumns varchar(max)
set @IndexColumns=''
set @IncludedColumns=''
declare CursorIndexColumn cursor for
select col.name, ixc.is_descending_key, ixc.is_included_column
from sys.tables tb
inner join sys.indexes ix on tb.object_id=ix.object_id
inner join sys.index_columns ixc on ix.object_id=ixc.object_id and ix.index_id= ixc.index_id
inner join sys.columns col on ixc.object_id =col.object_id and ixc.column_id=col.column_id
where ix.type>0 and ix.is_primary_key=1 --(ix.is_primary_key=1 or ix.is_unique_constraint=1)
and schema_name(tb.schema_id)=@SchemaName and tb.name=@TableName and ix.name=@IndexName
order by ixc.key_ordinal
open CursorIndexColumn
fetch next from CursorIndexColumn into @ColumnName, @IsDescendingKey, @IsIncludedColumn
while (@@fetch_status=0)
begin
if @IsIncludedColumn=0
set @IndexColumns=@IndexColumns + @ColumnName + case when @IsDescendingKey=1 then ' DESC, ' else ' ASC, ' end
else
set @IncludedColumns=@IncludedColumns + @ColumnName +', '
fetch next from CursorIndexColumn into @ColumnName, @IsDescendingKey, @IsIncludedColumn
end
close CursorIndexColumn
deallocate CursorIndexColumn
set @IndexColumns = substring(@IndexColumns, 1, len(@IndexColumns)-1)
set @IncludedColumns = case when len(@IncludedColumns) >0 then substring(@IncludedColumns, 1, len(@IncludedColumns)-1) else '' end
-- print @IndexColumns
-- print @IncludedColumns
set @TSQLScripCreationIndex =''
set @TSQLScripDisableIndex =''
-- added check if index exists into @TSQLScripCreationIndex string and set the filegroup to PRIMARY to match the subscriber db
set @TSQLScripCreationIndex='IF NOT EXISTS (SELECT * FROM sys.indexes WHERE object_id = OBJECT_ID(N'''+@TableName+''') AND name = '''+@IndexName+''')
ALTER TABLE '+ QUOTENAME(@SchemaName) +'.'+ QUOTENAME(@TableName)+ ' ADD CONSTRAINT ' + QUOTENAME(@IndexName) + @is_unique_constraint + @is_primary_key + +@IndexTypeDesc + '('+@IndexColumns+') '+
case when len(@IncludedColumns)>0 then CHAR(13) +'INCLUDE (' + @IncludedColumns+ ')' else '' end + CHAR(13)+' WITH (' + @IndexOptions+ ') ON [PRIMARY];'+ CHAR(13) -- ON ' + QUOTENAME(@FileGroupName) + ';'
print @TSQLScripCreationIndex
--print @TSQLScripDisableIndex
fetch next from CursorIndex into @SchemaName, @TableName, @IndexName, @is_unique_constraint, @is_primary_key, @IndexTypeDesc, @IndexOptions, @FileGroupName
end
close CursorIndex
deallocate CursorIndex
The output was exactly what I needed! (sorry this is a little fuzzy)
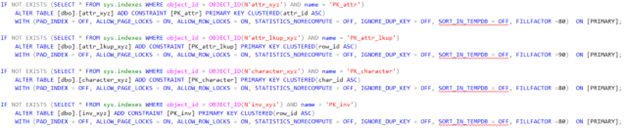
I put the above script into a job on the subscriber that will run every day. That way if a new snapshot is taken and the needed indexes get removed because of the strange inconsistencies in replication, the job will put them back or can be run manually to create anything that is missing.
Once the missing indexes were created on the subscriber, all replication latency went away almost immediately.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. Visit us at www.sqlrx.com!
Session expired
Please log in again. The login page will open in a new tab. After logging in you can close it and return to this page.
[…] Lori Brown provides a good tip: […]