Menu
In Parts 1 and 2 of this blog series the author discussed various aspects of SQL Server indices such as:
https://blog.sqlrx.com/2017/10/26/rx-for-demystifying-index-tuning-decisions-part-1/
https://blog.sqlrx.com/2017/11/02/rx-for-demystifying-index-tuning-decisions-part-2/
Part 3 covers the following topic:
Query plans have already been mentioned as being useful for query tuning. They can be invaluable for determining which part of a query causes performance issues, which indices are used, and HOW the indices are accessed, e.g., randomly or sequentially. A full discussion of query plans is beyond the scope of this presentation, but graphical plans are used most often. Graphical plans come in two forms: Estimated (predicted behavior) and Actual (actual behavior). XML plans contain additional information, but they are difficult to read even with an XML editor. Querying the XML data can provide invaluable information, but the queries to extract this information can consume a great deal of CPU time, especially when many complex plans must be examined, so it is best to peruse this kind of data on a server that is not used for production work whenever possible.
It is important for any database analyst to have a basic understanding of how to read query plans. These plans are graphical flow diagrams of how the query will be executed and what information will flow from one operator to another. The diagrams flow from bottom right to top left, and quite often the most crucial operators are near the right and sometimes near the bottom as well. Each node in the tree structure is represented by an icon and specifies the logical operator that will be used to execute that portion of the query. A popup appears displaying details about the operator when the mouse pointer is placed over an operator. This information is also available, and often easier to read, via the properties window (F4 in SSMS or right-click the node and click Properties). Each node is related to a parent node by arrows whose width is proportional to the number of rows returned by the operator. Note: The actual number of rows is used when available. Otherwise, the estimated number of rows is used. Sometimes, these are vastly different and these differences often indicate that statistics are not up-to-date or sufficiently comprehensive.
Large operators may run on parallel threads because the single-threaded version would run too long. For parallel queries that involve multiple threads/CPUs the node properties will display information about the operating system threads used. Parallelized nodes have graphical indicators, two arrows on a beige circle, to inform the viewer that the operator will be divided into multiple pieces for execution as shown in Figure 1 and Figure 2.

Figure 1: Query Plan Parallelism Operator
It is important to know what the most common data access operators are, as well as how to interpret them. An index seek operator indicates the retrieval of one or more rows using keys. Clustered or NonClustered indicate the type of index that is accessed, and a NonClustered Index Seek could possibly indicate the use of a covering index. Key and RID Lookups indicate a lookup of a row using the row ID or clustering key (heap or clustered index) to obtain information from the record that is not contained in the nonclustered index that was used for primary access. Key and RID Lookup operators are most often associated with a nested loop operator and a nonclustered seek operator. The Key and RID Lookup operators usually produce output, but not always. When they are present, the output column list indicates a possible opportunity to add those columns to the nonclustered index to create a covering index for this query. When the output column is missing, these operators are used to effect a join. A simple way to determine whether output columns exist is to view the Output List that is displayed for the operator popup like the list shown in Figure 3. Index Scan (Clustered or NonClustered) operators scan ALL rows of the index even if a where clause is used. Scan operators read ALL rows from a table or clustered index regardless of the where clause. All scans should be avoided a much as possible unless the tables are small. Examples of a clustered index scan operator and its properties are shown in Figure 2 and Figure 3.
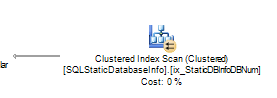
Figure 2: Clustered Index Scan Operator Graphic
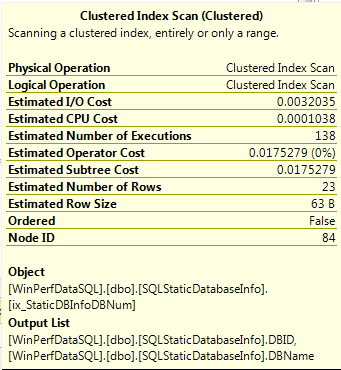
Figure 3: Clustered Index Scan Operator Properties
Other commonly used operators include nested loop, bitmap, and hash match. Nested Loops perform inner join, left outer join, left semi join, and left anti semi join logical operations. These operators are potentially very deceptive because although each iteration of a loop might be very efficient, there may be millions of iterations. Bitmap operators may speed up query execution by eliminating rows with key values that cannot produce any join records before passing rows through another operator such as a Parallelism operator. Hash Match operators build hash tables by computing a hash value for each row from its input. These are usually very bad and frequently indicate that the query and its joins should be rewritten.
The plan for the query below (originally covered in Part 2)….
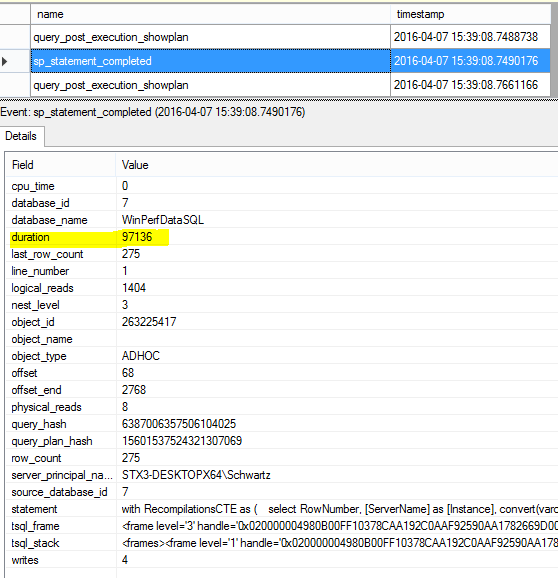
XEvents Statement Completed Sample Output
…is shown in Figure 4 and the properties for the nonclustered index scan are shown in Figure 5. The highlighted portions illuminate some important aspects of the query plan. The first one highlights the missing index recommendation and illustrates the key and included columns for the suggested index that would make this query run faster. The second highlight emphasizes the hash match, and the last one illustrates why the nonclustered index scan occurred. Specifically, the EventClass column was used by the index scan operator to look up records in the table with values of 166 because no appropriate index existed on the CompletedEventText table. The output columns, RowNumber and QueryChecksum, were returned by the index scan operator. It is important to note that the missing index recommendation specifies the same columns that are shown in the Output List in Figure 5. Generally speaking, index and table scan operators do not produce missing index recommendations, which will be discussed in more detail later in this series. Note: Prior to SQL Server 2014, the author had never observed an index scan operator that produced a missing index recommendation. This appears to be a function of the new Cardinality Estimator that was implemented in SQL Server 2014 and requires that the database compatibility level be set to SQL Server 2014 or later to use it. Otherwise, the old estimator that goes back to SQL Server 7.0 is used. Further information regarding the cardinality estimator can be found at https://blogs.technet.microsoft.com/dataplatform/2017/03/22/sql-server-2016-new-features-to-deal-with-the-new-ce/.
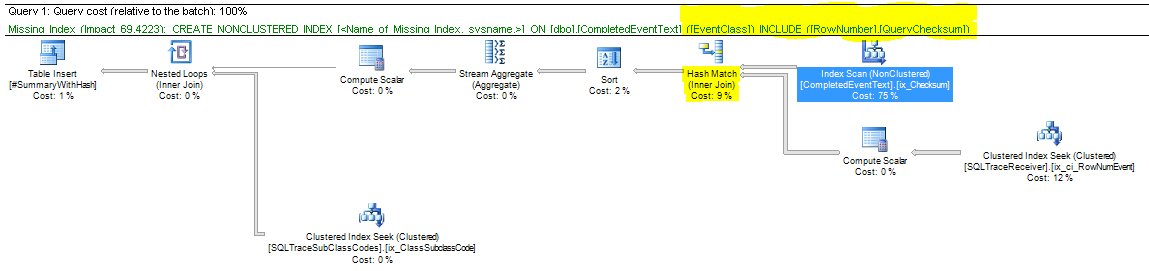
Figure 4: Query Plan with Hash Match and Index Scan Operators
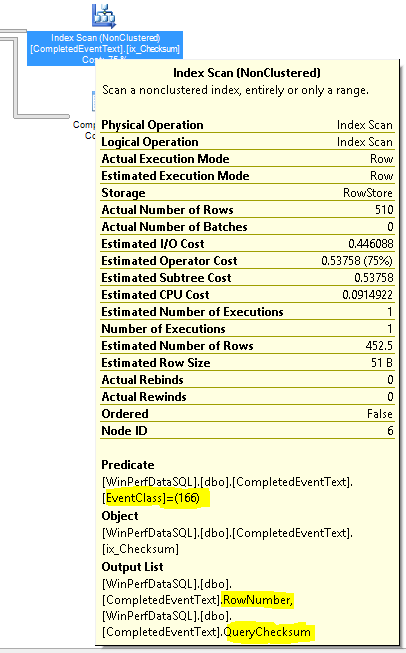
Figure 5: Index Scan Operator Properties from Query Plan with Hash Match and Index Scan
The next article in this blog series will cover the query optimizer. Until then….happy tuning and please contact us with any questions.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. Visit us at www.sqlrx.com!
Session expired
Please log in again. The login page will open in a new tab. After logging in you can close it and return to this page.
[…] https://blog.sqlrx.com/2017/11/09/rx-for-demystifying-index-tuning-decisions-part-3/ […]
[…] https://blog.sqlrx.com/2017/11/09/rx-for-demystifying-index-tuning-decisions-part-3/ […]
[…] https://blog.sqlrx.com/2017/11/09/rx-for-demystifying-index-tuning-decisions-part-3/ […]