Menu
Due to the holiday week, this part will be shorter than usual. In Parts 1 through 7 of this blog series the author discussed various aspects of SQL Server indices such as:
https://blog.sqlrx.com/2017/10/26/rx-for-demystifying-index-tuning-decisions-part-1/
https://blog.sqlrx.com/2017/11/02/rx-for-demystifying-index-tuning-decisions-part-2/
https://blog.sqlrx.com/2017/11/09/rx-for-demystifying-index-tuning-decisions-part-3/
https://blog.sqlrx.com/2017/11/16/rx-for-demystifying-index-tuning-decisions-part-4/
https://blog.sqlrx.com/2017/11/30/rx-for-demystifying-index-tuning-decisions-part-5/
https://blog.sqlrx.com/2017/11/30/rx-for-demystifying-index-tuning-decisions-part-6/
https://blog.sqlrx.com/2017/12/07/rx-for-demystifying-index-tuning-decisions-part-7/
Part 8 contains discusses how to determine missing indices and their estimated impact (if implemented) as well as incorporating missing index recommendations either into existing indices or into as few new indices as possible.
SQL Server monitors missing index warnings (same ones as shown in query plans) and records the estimates of the relative cost of not having the recommended index as queries execute. I/O plays a dominant role in these statistics because the expected I/O amounts affect estimated cost and improvement factors. Execution counts also affect these numbers. The impact shown in Figure 9 is quite high and indicates that the query could make good use of the recommended index if it were implemented. In this example, the key lookup accounts for all the work performed by the query and is no doubt the reason for the missing index recommendation.
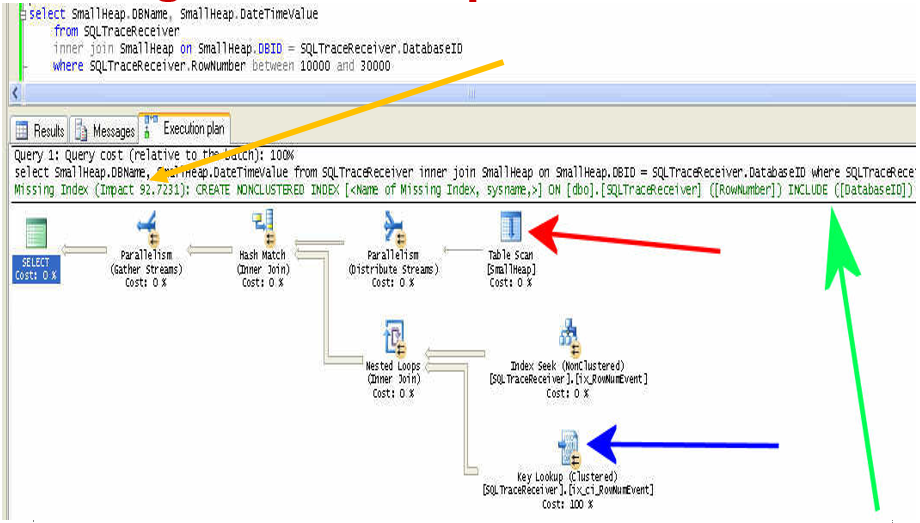
Figure 9: Missing Index Example
Four views are used to derive the missing index statistics recommendations:
These four DMV/DMFs are dependent upon the missing index warnings that would appear in SSMS query plans. Although Table 13 does not show the actual index recommendations, it does show the numerics involved. Improvement Measure and User Impact are frequently good indicators of potentially useful indices. The number of query executions, referred to as user seeks in the DMV, is also a good indicator of an index that would benefit multiple query executions. This metric can also be useful for locating specific queries that might need this index because the counts can sometimes limit the search candidates. The reader should note that the names of some tables are repeated multiple times, indicating that multiple index recommendations were suggested by SQL Server. Generally, improvement measures of one million or higher should be considered seriously. The formula for improvement measure is as follows: avg_total_user_cost * avg_user_impact * (user_seeks + user_scans). Note: User_scans are almost always zero. Although the 894 million value shown in Table 13 may seem very high, the values shown in Table 14 emphasize how bad things can get.

Table 13: Consolidated Missing Index DM Views Sample Report

Table 14: Extremely High Missing Index Values
Table 15 summarizes the recommendations by table and shows another way this data can be viewed. The number of recommended indices for the jkl_abc.dbo.dly_st_mtc_smy, jkl_abc.dbo.hr_st_mtc_smy, and jkl_def.dbo.nglentUS2017 tables are instructive because they are 28, 52, and 51, respectively. Clearly, these cannot be implemented without creating significant amounts of overhead and repeating the excessive indexing problems cited earlier in this blog series. Clearly, as indicated by the Total Improvement Measure and the Recommended Index Count, the jkl_abc.dbo.dly_st_mtc_smy table needs a great deal of indexing tuning help. Resolving the jkl_def.dbo.KDS_spofsvc table’s indexing issues should be simpler to resolve because SQL Server only recommended three indices.
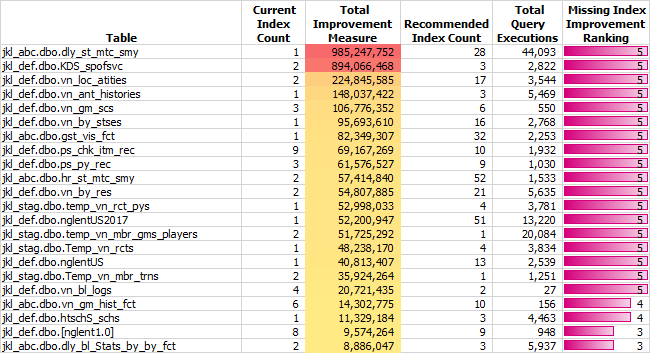
Table 15: Missing Index Improvement by Table
It is also important to realize that these recommendations are driven by the queries, so very often many similar recommendations will be provided by SQL Server since it does not compare existing indices with recommended ones. The recommendations often make extensive use of included columns even to the extent that sometimes almost all of the columns in the table are recommended for inclusion. SQL Server treats every index as if it were new, even if an existing index could be modified slightly to accommodate the recommendation. The duplication issue is shown clearly in Table 16. All of these recommendations are for the same table and only show those recommendations that began with CID as the first key. Most of these recommendations are not worth implementing given the low improvement measure, but the 274,170 one might be worth considering. The table also shows that 35 indices already exist on this table, so adding more indices is not advisable unless absolutely necessary. Even then, every opportunity to drop an existing index to make room for a new one should be exercised. Using a cross-tabular format like the one below makes comparing the various recommendations much easier. In addition, the reader should note the operator in parentheses (= or <). The equality ones make things much easier because as long as both CID and CO are present, the order is not as critical. Therefore, an existing index that had CO as the first key already might be useful if the CID key were added. Using the color-coded cross-tab format also makes it much easier to identify the included columns that are common to or different from those of the other missing index recommendations.
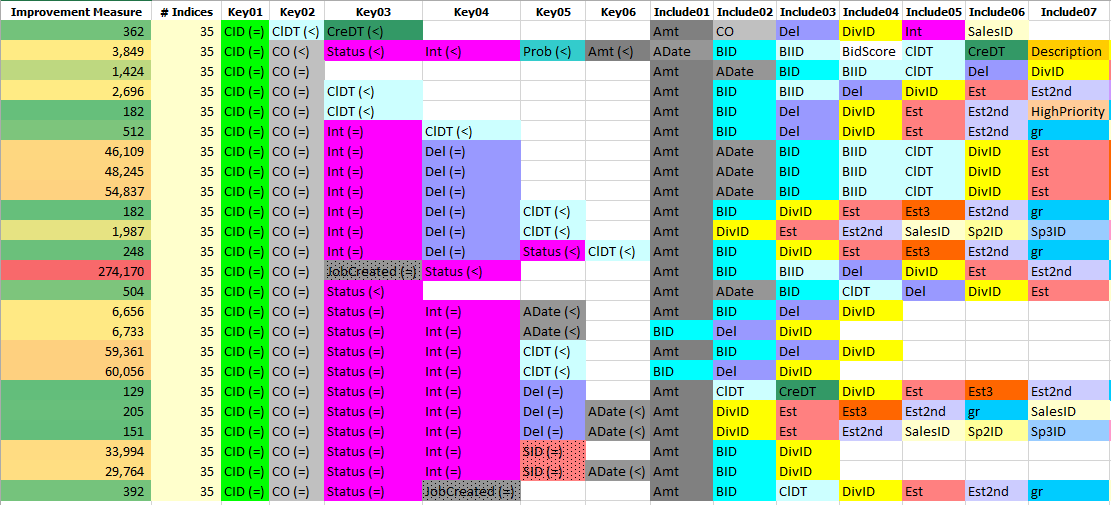
Table 16: Missing Index Cross-Tab Example
Some articles suggest that the included columns in missing index recommendations are in no particular order. As discussed in the article that is available at the following link, the included columns are produced in TABLE column order, regardless of the order specified in the query that generated the missing index recommendation: https://blog.sqlrx.com/2017/06/02/query-tuning-and-missing-index-recommendations. Two other important points should be made regarding these recommendations and the DMVs. The cited DMVs also provide the data for the Database Tuning Advisor, although Microsoft says the tool is more comprehensive and “much better.” It is often tempting to assume that any poorly performing query will generate some sort of warning, especially those that perform full scans. As cited previously, versions of SQL Server prior to SQL Server 2014 never seemed to generate any missing index recommendations for queries that performed full table or index scans. Under certain conditions, the new optimizer seems to generate missing index recommendations for some full scans. However, if the query makes extensive use of numerous nested loops, recommendations will often still not be produced by SQL Server. For further information regarding missing index DMVs, please consult the following links:
http://blogs.msdn.com/b/bartd/archive/2007/07/19/are-you-using-sql-s-missing-index-dmvs.aspx and http://www.mssqltips.com/tip.asp?tip=1634.
This tool replays a single, previously captured workload, and enables the analyst to determine how this workload might perform on a new server, with a new version of SQL Server, or using a revised index structure. Unfortunately, the analyst does not have a great deal of control over how the workload is replayed and it uses a single T-SQL script or trace table replay quite often. The analyst can choose to manually or automatically implement the recommendations. Since it uses the missing index DMVs, it often implements many of the indices with the highest factors without regard to existing indices, i.e., no consideration is given to whether functionality would be duplicated or whether any existing index could be adjusted to satisfy the query’s need. This often results in significant duplication of indices, i.e., the overlapping indices that were discussed earlier. Since it often favors covering indices, it frequently implements indices that duplicate large portions of the table in order to make the index a covering one. The new indices use the _DTA prefix to distinguish them from user-generated indices.
Several methods exist for replaying a workload. One method is to replay the workload using Profiler and reload the database after each test. Other methods must be used when the databases being tested are huge, therefore requiring many hours to reload. One method is to use a read-only database, but this method does not work as well as it once did. On earlier releases of SQL Server, a query that changed the database would execute up to the point at which the database change was attempted. However, attempting this method on SQL Server 2016 does not work because the query fails immediately. Another method is to run the inquiry-only queries in parallel while controlling thread levels, and run the update queries sequentially utilizing a begin tran/rollback tran for each query that changes the database. This causes the updates to take longer, not only because the queries are run sequentially, but also because work is required to roll the transaction out. Fortunately, the work performed by the query is recorded separately from the rollback portion, so before-and-after query performance comparison is still easy to do. A variation of the last method is to execute only the queries that work with specific tables. This allows the testing to be more surgical.
Index tuning can be difficult, but it definitely can be accomplished. It is essential to understand how queries and indices interact as well as how to read and understand Query Plans, Index Usage and Operational Stats metrics, and Missing Index recommendations and DMVs. Capturing performance data from SQL Server instance that has been running for as long as possible is critical to insure that index usage is fully understood. The longer the instance has been running, the more comprehensive these metrics will be. Using some form of SQL trace replay is the ONLY way to perform comprehensive index tuning because it is surprising how many times index usage will be counterintuitive. Therefore, the analyst MUST see it in action! Significant index redesign can often be completed with 2-5 weeks’ worth of effort, and the results can be quite dramatic as shown in this series.
This concludes the Rx for Demystifying Index Tuning Decisions blog series. Hopefully, the reader has found the series enlightening and useful. Please let us know if you have any questions or suggestions for additional articles. Best of luck with all your tuning efforts and please contact us with any questions.
For more information about blog posts, concepts and definitions, further explanations, or questions you may have…please contact us at SQLRx@sqlrx.com. We will be happy to help! Leave a comment and feel free to track back to us. Visit us at www.sqlrx.com!